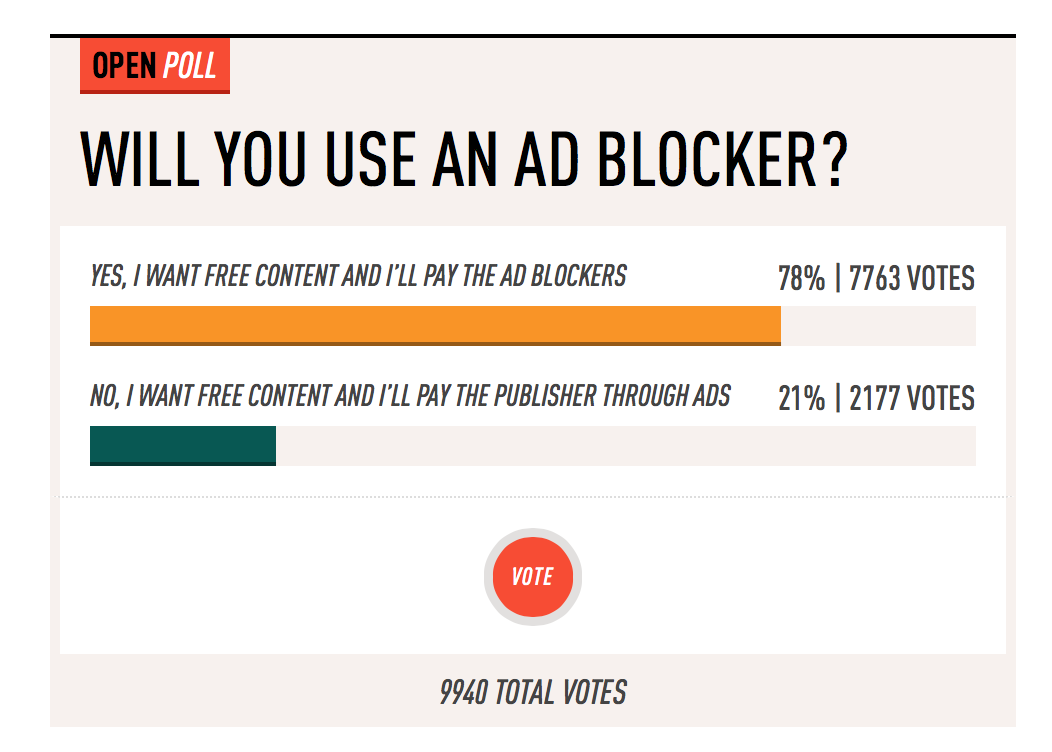
One of the biggest challenges of shipping a product is knowing when to put on the shipping goggles.
The shipping goggles make you less sensitive to little nits and scrapes and things that might be able to be a little bit better, but really don’t need to be right now. Stuff that we could tweak, but really shouldn’t be grabbing our attention given all the other high value bits we need to hit.
It’s sort of like squinting – you lose the detail, but you can still see the overall big picture shape, form, and function. Your peripheral vision shrinks, but the center is still bright. Knowing when to squint is a good thing to know.
It’s not that the details don’t matter. They do, but details aren’t fixed – they’re relative. And of course any time you talk about details mattering, you’re speaking in very broad generalizations. Some matter, some don’t. Some never matter, some matter later, but not now. And some really matter now and can’t wait for later. Like everything, there are varying degrees.
Part of training yourself to ship is to recognize what details are really worth nitpicking and when. There are no hard and fast rules here – it just takes judgement and experience. These are skills that build over time. Once you’ve been around it for a while you tend to improve your sensitivity to what’s worth doing before you ship and what can wait until later.
And BTW, nitpicking may be construed as a pejorative, but I don’t believe it is. Nitpicking is a valuable skill, as long you deploy it at the right time for the right reasons. One of the penalties of nitpicking at the wrong time is that nitpicking often attracts a crowd. Someone nitpicks this which is an invitation for someone else to nitpick that. And before you know it, half a dozen people are spending time discussing tiny details that really don’t demand that level of attention.
Again, there are no facts around when it’s worth nitpicking and what’s worth nitpicking – I’m only speaking to the awareness how situations unfold.
We can all get better at this. I’ve been shipping stuff for years, but I still have to get better at recognizing the right moments to bring up certain things. I definitely fall into the trap of spending time making changes to things in the 11th hour that are really perfectly fine and can be addressed later if necessary. I absolutely find myself regretting going down a rabbit hole that really didn’t need to be investigated. I still find myself distracting others with change requests or suggestions that really didn’t need to cloud their vision and sap their attention. It’s hard!!
As we close in on a big launch ourselves, I’m reminded of how important it is to keep time and place and impact in mind when bringing small things up. Again, it’s not that they aren’t important, it’s that they may not be important now. Everything has a cost and the cost of breaking attention goes up during crunch time.