Back in November, we noticed something odd happening with large uploads to Amazon S3. Uploads would pause for 10 seconds at a time and then resume. It had us baffled. When we started to dig, what we found left us with more questions than answers about S3 and AWS networking.
We use Amazon S3 for file storage. Each Basecamp product stores files in a primary region, which is replicated to a secondary region. This ensures that if any AWS region becomes unavailable, we can switch to the other region, with little impact to users uploading and downloading files.
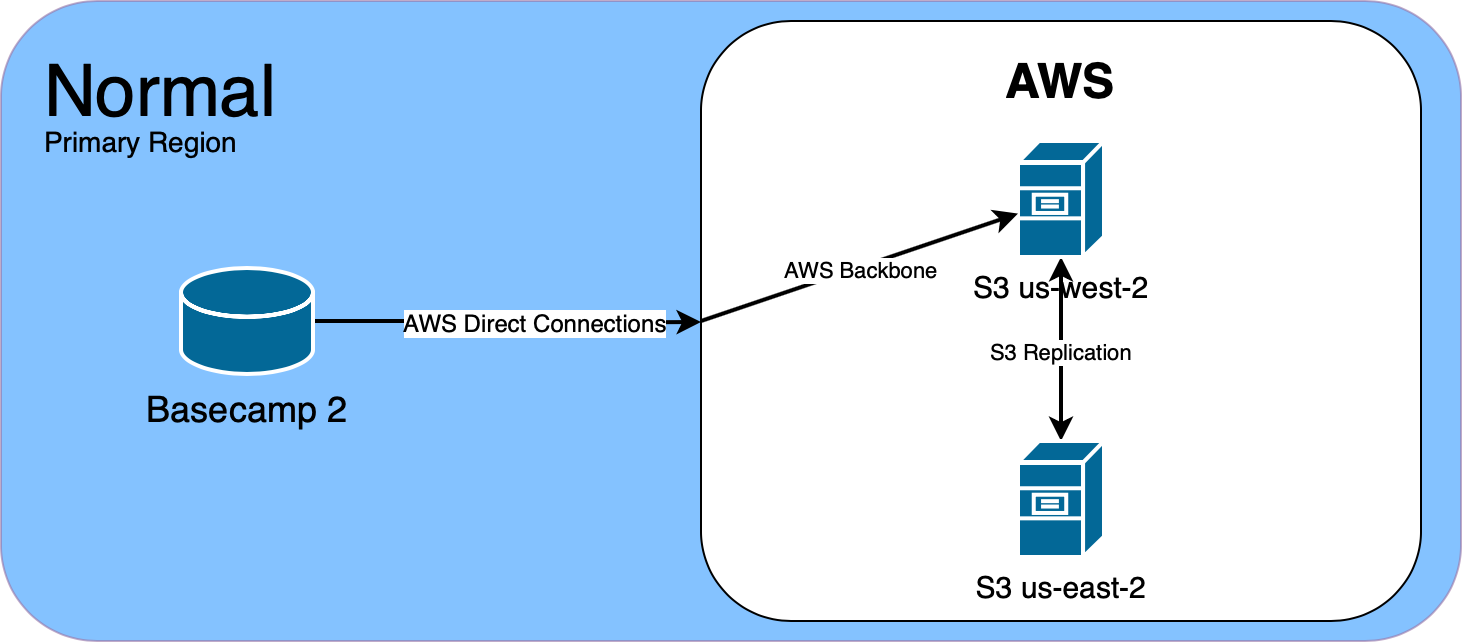
Back in November, we started to notice some really long latencies when uploading large files to S3 in us-west-2, Basecamp 2’s primary S3 region. When uploading files over 100MB, we use S3’s multipart API to upload the file in multiple 5MB segments. These uploads normally take a few seconds at most. But we saw segments take 40 to 60 seconds to upload. There were no retries logged, and eventually the file would be uploaded successfully.
[AWS S3 200 0.327131 0 retries]
[AWS S3 200 61.354978 0 retries]
[AWS S3 200 1.18382 0 retries]
[AWS S3 200 43.891385 0 retries]
For our applications that run on-premise in our Ashburn, VA datacenter, we push all S3 traffic over redundant 10GB Amazon Direct Connects. For our Chicago, IL datacenter, we push S3 over public internet. To our surprise, when testing uploads from our Chicago datacenter, we didn’t see any increased upload time. Since we only saw horrible upload times going to us-west-2, and not our secondary region in us-east-2, we made the decision to temporarily promote us-east-2 to our primary region.
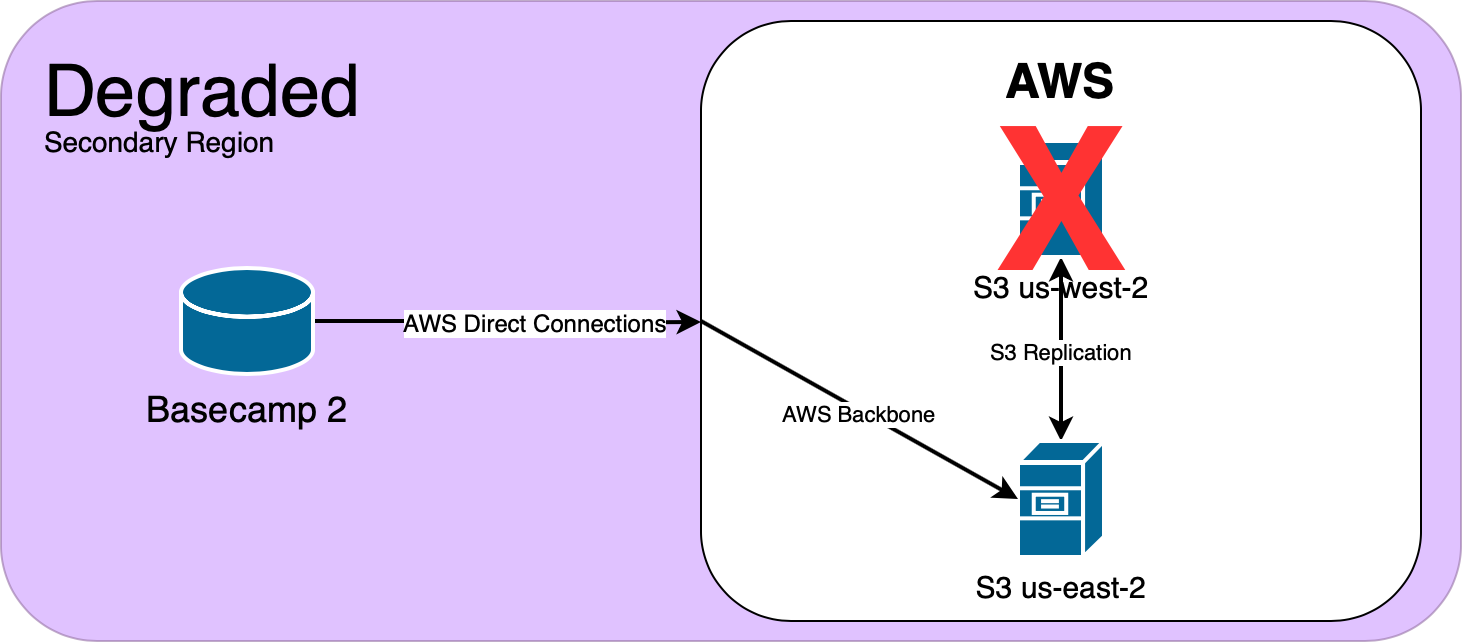
Now that we were using S3 in us-east-2, our users were no longer feeling the pain of high upload time. But we still needed to get to the bottom of this, so we opened a support case.
Our initial indication was that our direct connections were causing slowness when pushing uploads to S3. However, after testing with mtr, we were able to rule out direct connect packet loss and latency as the culprit. As AWS escalated our case internally, we started to analyze the TCP exchanges while we upload files to S3.
The first thing we needed was a repeatable and easy way to upload files to S3. Taking the time to build and set up proper tooling when diagnosing an issue really pays off in the long run. In this case, we built a simple tool that uses the same Ruby libraries as our production applications. This ensured that our testing would be as close to production as possible. It also included support for multiple S3 regions and benchmarking for the actual uploads. Just as we expected, uploads to both us-west regions were slow.
irb(main):023:0> S3Monitor.benchmark_upload_all_regions_via_ruby(200000000)
region user system total real
us-east-1: 1.894525 0.232932 2.127457 ( 3.220910)
us-east-2: 1.801710 0.271458 2.073168 ( 13.369083)
us-west-1: 1.807547 0.270757 2.078304 ( 98.301068)
us-west-2: 1.849375 0.258619 2.107994 (130.012703)While we were running these upload tests, we used tcpdump to output the TCP traffic so we could read it with Wireshark and TShark.
$ tcpdump -i eth0 dst port 443 -s 65535 -w /tmp/S3_tcp_dump.logWhen analyzing the tcpdump using Wireshark, we found something very interesting: TCP retransmissions. Now we were getting somewhere!
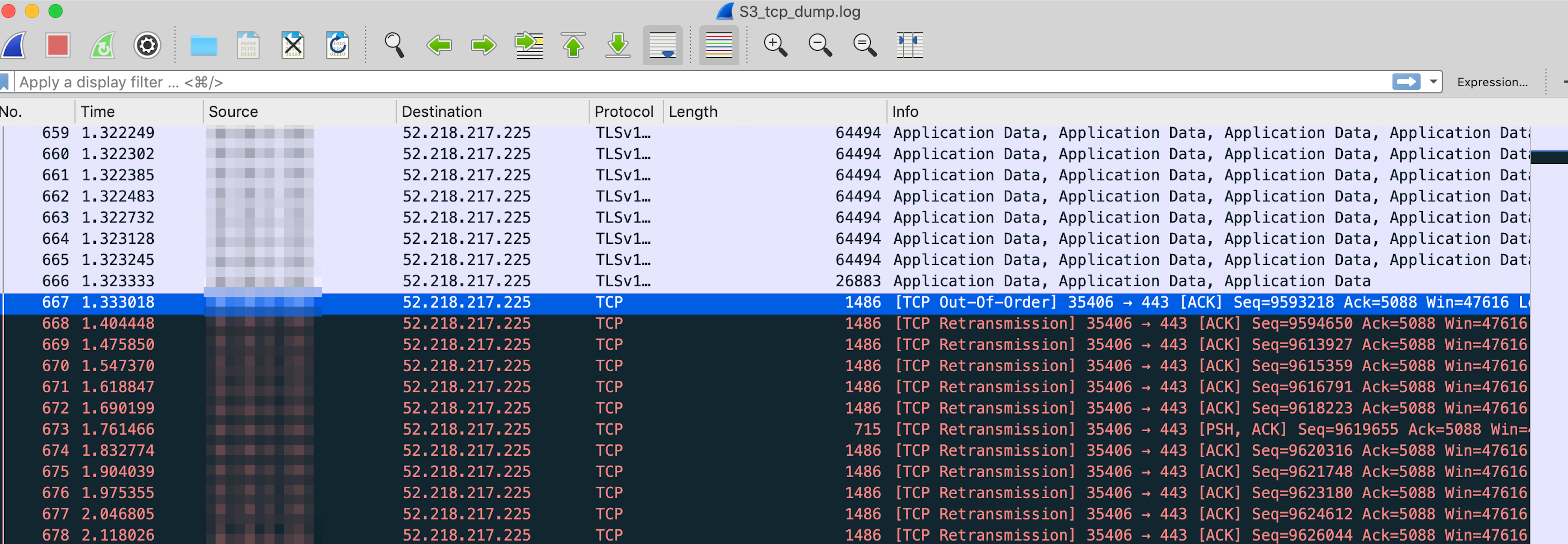
Analysis with TShark gave us the full story of why we were seeing so many retransmissions. During the transfer of 200MB to S3, we would see thousands of out-of-order packets, causing thousands of retransmissions. Even though we were seeing out-of-order packets to all US S3 regions, these retransmissions compounded with the increased round trip time to the us-west regions is why they were so much worse than the us-east regions.
# tshark -r S3_tcp_dump.log -q -z io,stat,1,"COUNT(tcp.analysis.retransmission) tcp.analysis.retransmission","COUNT(tcp.analysis.duplicate_ack)tcp.analysis.duplicate_ack","COUNT(tcp.analysis.lost_segment) tcp.analysis.lost_segment","COUNT(tcp.analysis.fast_retransmission) tcp.analysis.fast_retransmission","COUNT(tcp.analysis.out_of_order) tcp.analysis.out_of_order"
Running as user "root" and group "root". This could be dangerous.
===================================================================================
| IO Statistics |
| |
| Duration: 13.743352 secs |
| Interval: 1 secs |
| |
| Col 1: COUNT(tcp.analysis.retransmission) tcp.analysis.retransmission |
| 2: COUNT(tcp.analysis.duplicate_ack)tcp.analysis.duplicate_ack |
| 3: COUNT(tcp.analysis.lost_segment) tcp.analysis.lost_segment |
| 4: COUNT(tcp.analysis.fast_retransmission) tcp.analysis.fast_retransmission |
| 5: COUNT(tcp.analysis.out_of_order) tcp.analysis.out_of_order |
|---------------------------------------------------------------------------------|
| |1 |2 |3 |4 |5 | |
| Interval | COUNT | COUNT | COUNT | COUNT | COUNT | |
|--------------------------------------------------| |
| 0 <> 1 | 28 | 11 | 0 | 0 | 0 | |
| 1 <> 2 | 3195 | 0 | 0 | 0 | 5206 | |
| 2 <> 3 | 413 | 0 | 0 | 0 | 1962 |
...
| 13 <> Dur| 0 | 0 | 0 | 0 | 0 | |
===================================================================================What’s interesting here is that we see thousands of our-of-order packets when transversing our direct connections. However, when going over the public internet, there are no retransmissions or out-of-order packets. When we brought these findings to AWS support, their internal teams reported back that “out-of-order packets are not a bug or some issue with AWS Networking. In general, the out-of-order packets are common in any network.” It was clear to us that out-of-order packets were something we’d have to deal with if we were going to continue to use S3 over our direct connections.

Thankfully, TCP has tools for better handling of dropped or out-of-order packets. Selective Acknowledgement (SACK) is a TCP feature that allows a receiver to acknowledge non-consecutive data. Then the sender can retransmit only missing packets, not the out-of-order packets. SACK is nothing new and is enabled on all modern operating systems. I didn’t have to look far until I found why SACK was disabled on all of our hosts. Back in June, the details of SACK Panic were released. It was a group of vulnerabilities that allowed for a remotely triggered denial-of-service or kernel panic to occur on Linux and FreeBSD systems.
In testing, the benefits of enabling SACK were immediately apparent. The out-of-order packets still exist, but they did not cause a cascade of retransmissions. Our upload time to us-west-2 was more than 22 times faster than with SACK disabled. This is exactly what we needed!
irb(main):023:0> S3Monitor.benchmark_upload_all_regions_via_ruby(200000000)
region user system total real
us-east-1: 1.837095 0.315635 2.152730 ( 2.734997)
us-east-2: 1.800079 0.269220 2.069299 ( 3.834752)
us-west-1: 1.812679 0.274270 2.086949 ( 5.612054)
us-west-2: 1.862457 0.186364 2.048821 ( 5.679409)The solution would not just be as simple as just re-enabling SACK. The majority of our hosts were on new-enough kernels that had the SACK Panic patch in place. But we had a few hosts that could not upgrade and were running vulnerable kernel versions. Our solution was to use iptables to block connections with a low MSS value. This block allowed for SACK to be enabled while still blocking the attack.
$ iptables -A INPUT -p tcp -m tcpmss --mss 1:500 -j DROPAfter almost a month of back-and-forth with AWS support, we did not get any indication why packets from S3 are horribly out of order. But thanks to our own detective work, some helpful tools, and SACK, we were able to address the problem ourselves.

Figures. My experience with AWS has been that it seems really slick at first, but you eventually end up with some kind of performance issue that AWS themselves can’t debug. They act like they want to make cloud computing easier, but just look at the amount of technical skills required JUST do debug the issue. Ridiculous.
Bravo!
I would take a wild as educated wild ass guess and say that your out-of-order tcp segments may be due to BGP inbound path selection. Are you advertising the same Public IP block out of your ISP as you are the AWS direct connect(s)? Great Article, I love a good technical war story…
John,
Not sure if that was the exact iptables/netfilter rule you’re using, or just an abbreviated example, but I’d recommend the following instead (mostly based on Red Hat’s guidance from their advisory). It’s much faster and more efficient in terms of processing to immediately DROP in the PREROUTING chain of the `raw` table rather than within the default `filter` table’s INPUT chain, and using “-I” will also ensure it gets placed *before* any existing rules, which could otherwise mean that traffic with bad/low MSS values gets inadvertently accepted if it’s after matching ACCEPT entries.
Love the sleuthing; thank you for sharing!
# iptables -t raw -I PREROUTING -p tcp –tcp-flags SYN SYN -m tcpmss –mss 1:500 -j DROP
We were able to get through to AWS networking when we hit a bug but we had to do all research ourselves and get a bulletproof case for the issue. A couple of years ago we were moving infrastructure from AWS Classic to VPC. VPC used NAT Gateways. Everything moved without issues but when we moved infrastructure for literally the last client we started getting issues with SSL because sessions would drop suddenly once in a while. It took some time to figure out that sessions drop because data got corrupted in transit. We found that once in a while a single bit would get reversed in transit and it happened only with this one client and nowhere else. Also, it only happened with NAT Gateway in the path. In the end, we figured out how to make it easy to see with a very long HTTP request like /xxxx… that created a very long response. When broken bit corrupted a character within request header it became easily visible. It took AWS networking people several months to fix the issue but since then it was a trouble-free connection.
Use Backblaze. It’s faster and like 1/4th the cost of S3
So you’re saying that AWS was never out of order but the issue was that your hosts had SACK disabled, correct?
The packets from S3 are certainly out-of-order. However, the problem is mitigated by enabling SACK.
Very interesting write up and fix. Out-of-order packets on redundant interconnects are unfortunately very common due to multipath caused by ECMP-based routing. Were on-prem routing tables checked for equal cost paths?
Assuming you have multiple redundant interconnects. Run a TCP iPerf3 with >16 parallel streams to AWS. Make sure source port is not fixed. Do a subset of streams show poor performance? If so, you’re likely seeing multipath splitting traffic across interconnects with mismatched latency. I see it with my customers frequently (10Gbps interconnect at <50Mbps), and it's hard for us to troubleshoot due to the issue residing in upstream networks that the provider cannot audit. Likewise the issue can be bidirectional, so it's worth it to reverse the test as well. You'll still see out-of-order due to the nature of iperf, but the goal is to perform stream analysis.
Instead of tackling SACKs, you may want to check your BGP path MED on both sides of your links for traffic splitting. If you failover to one link, and the issue resolves, you have your culprit.
Thanks for the write-up!
Jake, we were able to eliminate the direct connections as the problem by testing over a single direct connect. Then we also were able to reproduce the issue on EC2 instance both inside and outside our VPC.
“On-premises”, not “on-premise”. The premises are the collected abstractions that make up a thing. The term as you used it is never singular.
“On-prem” is sexier, and using it prevents guys like you from posting public typo corrections :).
Thanks for sharing
can thia happen with aws elastic cache redis as well?
I don’t really understand where was the packet capture taken at- is it from uploading server itself? or some network device along the way? or AWS end of direct connect? (I don’t suppose this)
I’m struggling to understand how can something get out of order.. my assumption is that capture is taken on your uploading server so if something is out of order your server must have put it on the wire this way
hi John,
I don’t really think anything is out of order.. it’s just wireshark’s tcp analysis marking the packets this way because it doesn’t have any information from the opposite side. Problem is in your tcpdump filter where you capture only traffic from you towards S3 but no returning traffic. This way you (nor wireshark) can’t have real picture about what is happening on TCP level.
I think you’re experiencing slight packet loss on your direct connect link. Your ‘tcp out of order’ is in fact ‘tcp fast retransmission’ but wireshark’s tcp analysis engine cannot tell that as it doesn’t see any duplicate ACK received from other side.
I’m just pointing it out as you’re using ‘out-of-order’ phrase a lot in your article but it doesn’t make any sense. From sending side you have no way to know if other side received anything out of order. It’s just wireshark confusing you because you didn’t provide it full picture.
Next time I’d suggest to change the tcpdump filter to contain both sides (i.e. ‘src port 443 or dst port 443’). Having both sides of conversation (both flows if you want) is important for any packed level analysis.
Also I’d recommend to be very careful next time when it comes to sysctl and tcp internals. TCP is wild and complicated beast and doing any OS level tuning can be disastrous. I know Red Hat advised it and it surprised me they didn’t stress more how important and ubiquitous SACK is in modern networks.
Thanks @ondrej for this insight and the clear and helpful way you provided it.
The tshark output shows a non-zero duplicate_ack count for interval ‘0 1’. Maybe they did capture both sides in a subsequent capture and conflated the two captures in the post. Or?
Ondrej,
Thanks for thoughtful reply. I should have added in the post that we received confirmation from AWS support that out-of-order packets are common.
“On checking these uploads to S3, I was also able to see a number of TCP retransmissions due to out-of-order packets. The tests I ran used the default VPC Endpoint and it looks like the out-of-order packets are common with the EC2 Network.”
As a Basecamp user, I’ve had a few situations in the recent past where file uploads were atrociously slow and thought it was just me!
Thanks for publishing this level of technical detail. It’s helpful for several solutions we’ve built that integrate with S3, and more importantly, it’s great to have credible information to refer to. Also, seeing your process reminds me of why we love Basecamp so much!
David, thank you for your kind words. If you ever see slow uploads to Basecamp, drop us a line at [email protected].
Did you try playing around/reducing MTU?