My name is David Heinemeier Hansson, and I’m the CTO and co-founder of Basecamp, a small internet company from Chicago that sells project-management and team-collaboration software.
When we launched our main service back in 2004, the internet provided a largely free, fair, and open marketplace. We could reach customers and provide them with our software without having to ask any technology company for permission or pay them for the privilege.
Today, this is practically no longer true. The internet has been colonized by a handful of big tech companies that wield their monopoly power without restraint. This power allow them to bully, extort, or, should they please, even destroy our business – unless we accept their often onerous, exploitive, and ever-changing terms and conditions.
We’re hiring a programmer to join our Research & Fidelity team to help shape the front end of our Rails applications and expand our suite of open-source JavaScript frameworks. We’re accepting applications for the next two weeks with a start date in early April.
We strongly encourage candidates of all different backgrounds and identities to apply. Each new hire is an opportunity for us to bring in a different perspective, and we are always eager to further diversify our company. Basecamp is committed to building an inclusive, supportive place for you to do the best and most rewarding work of your career.
ABOUT THE JOB The Research & Fidelity team consists of two people, Sam Stephenson and Javan Makhmali, whose work has given rise to Stimulus, Turbolinks, and Trix—projects that exemplify our approach to building web applications. You’ll join the team and work with them closely.
In broad terms, Research & Fidelity is responsible for the following:
Designing, implementing, documenting, and maintaining front-end systems for multiple high-traffic applications
Building high-fidelity user interface components with JavaScript, HTML, and CSS
Assisting product teams with front-end decisions and participating in code reviews
Tracking evergreen browser changes and keeping our applications up-to-date
Extracting internal systems and processes into open-source software and evolving them over time
As a member of the R&F team at Basecamp, you’ll fend off complexity and find a simpler path. You’ll fix bugs. You’ll go deep. You’ll learn from us and we’ll learn from you. You’ll have the freedom and autonomy to do your best work, and plenty of support along the way.
Our team approaches front-end work from an unorthodox perspective:
Our architecture is best described as “HTML over the wire.” In contrast to most of the industry, we embrace server-side rendered HTML augmented with minimal JavaScript behavior.
We implement features on a continuum of progressive enhancement. That means we have a baseline of semantic, accessible HTML, layered with JavaScript and CSS enhancements for desktop, mobile web, and our hybrid Android and iOS applications.
We believe designers and programmers should build UI together, and that HTML is a common language and shared responsibility. Our tools and processes are manifestations of this belief.
We are framework builders. We approach intractable problems from first principles to make tools that help make Basecamp’s product development process possible.
Here are some things we’ve worked on recently that might give you a better sense of what you’ll be doing day to day:
Working with a designer during Office Hours (our weekly open invitation) to review and revise their code
Researching Service Workers and building a proof-of-concept offline mode for an existing application
Creating a Stimulus controller to manage “infinite” pagination using IntersectionObserver
Investigating a Safari crash when interacting with <datalist> elements and filing a detailed report on WebKit’s issue tracker
Extracting Rails’ Action Text framework from the rich text system in Basecamp 3
Working with programmers from the iOS and Android teams to co-develop a feature across platforms
Porting Turbolinks from CoffeeScript to TypeScript and refactoring its test suite
Responding to a security report for our Electron-based desktop app and implementing a fix
ABOUT YOU We’re looking for someone with strong front-end JavaScript experience. You should be well-versed in modern browser APIs, HTML, and CSS. Back-end programming experience, especially with Ruby, is a plus but not a requirement. You won’t know how all the systems work on day one, and we don’t expect you to. Nobody hits the ground running. Solid fundamentals with software development, systems, troubleshooting, and teamwork pave the way.
You might have a CS degree. You might not. That’s not what we’re looking for. We care about what you can do and how you do it, not about how you got here. A strong track record of conscientious, thoughtful work speaks volumes.
This is a remote job. You’re free to work where you work best, anywhere in the world: home office, coworking space, coffeeshops. While we currently have an office in Chicago, you should be comfortable working remotely—most of the company does!
Managers of One thrive at Basecamp. We’re committed generalists, eager learners, conscientious workers, and curators of what’s essential. We’re quick to trust. We see things through. We’re kind to each other, look up to each other, and support each other. We achieve together. We are colleagues, here to do our best work.
We value people who can take a stand yet commit even when they disagree. And understand the value in others being heard. We subject ideas to rigorous consideration and challenge each other, but all remember that we’re here for the same purpose: to do good work together. That comes with direct feedback, openness to each others’ experience, and willingness to show up for each other as well as for the technical work at hand. We’re in this for the long term.
PAY AND BENEFITS Basecamp pays in the top 10% of the industry based on San Francisco rates. Same position, same pay, no matter where you live. The salary for this position is either $149,442 (Programmer) or $186,850 (Senior Programmer). We assess seniority relative to the team at Basecamp during the interviewing process.
Benefits at Basecamp are all about helping you lead a healthy life outside of work. We won’t treat your life as dead code to be optimized away with free dinners and dry cleaning. You won’t find lures to keep you coding ever longer. Quality time to focus on work starts with quality time to think, exercise, cook a meal, be with family and friends—time to yourself.
Work can wait. We offer fully-paid parental leave. We work 4-day weeks through the summer (northern hemisphere), enjoy a yearly paid vacation, and take a one-month sabbatical every three years. We subsidize coworking, home offices, and continuing education, whether professional or hobbyist. We match your charitable contributions. All on a foundation of top-shelf health insurance and a retirement plan with a generous match. See the full list.
HOW TO APPLY Please send an application that speaks directly to this position. Show us your role in Basecamp’s future and Basecamp’s role in yours. Address some of the work we do. Tell us about a newer (less than five years old) web technology you like and why.
We’re accepting applications until Sunday, February 2, 2020, at 9:00PM US-Central time. There’s no benefit to filing early or writing a novel. Keep it sharp, short, and get across what matters to you. We value great writers, so take your time with the application. We’re giving you our full attention.
We expect to take two weeks to review all applications. You’ll hear from us by February 14 about whether you’ve advanced to the written code review part of the application process. If so, you’ll submit some code you’re proud of, review it, and tell its story. Then on to an interview. Our interviews are one hour, all remote, with your future colleagues, on your schedule. We’ll talk through some of your code and some of ours. No gotchas, brainteasers, or whiteboard coding. We aim to make an offer by March 20 with a start date in early April.
At Basecamp we have an internal project called “Your proudest moments”. My colleague Dan set it up so that people at Basecamp could share anything we’re proud of. So far people have shared impressive, really feel-good accomplishments, such as performing complicated house renovations without professional help, writing books, or taking their parents on an unforgettable vacation.
This post comes from my first contribution to this project. As I told them, it went to “Your proudest moments” because we don’t have a “Your most useless and pointless self-inflicted programming hours” project, that would have been the best fit. Still, this quite a ridiculous thing to do made me super proud, and I also had a lot of fun doing it.
All the 50 stars!
Advent of Code is an advent calendar of programming puzzles that’s been happening since 2015, made by Eric Wastl. Every day from 1st to 25th December a new puzzle with 2 parts gets released and for each part solved you get a star. The goal is to collect all 50 stars to save Christmas. All the problems follow a story normally involving the space, a spaceship, elves, reindeers and Santa. The difficulty increases as the days pass. First ones are simpler, but then they start getting complicated and laborious. Some of them are pretty tricky! They aren’t necessarily super hard algorithmically, binary search, BFS, Dijkstra, Floyd–Warshall, A*… might be all you need but I can easily take several hours to finish each one. This year there was also a bit of modular arithmetic that I loved and a little bit of trigonometry. The problems are quite amazing. This year for example included things like a Pong game in Intcode, a made-up assembly language (you had to program the joystick movements and feed them to the program) and a text-based adventure game in Intcode as well. It’s seriously cool.
the quality and thought behind the problems in AoC is really outstanding, you can feel the amount of work and dedication behind their preparation, and the result is challenging, engaging, and fun (CAVEAT: marriages may be harmed) https://t.co/CWnSgfTsTh
I’ve done it in 2016, 2017 and 2018, the first time in Ruby, then the last 2 years in Elixir. I never finish on the 25th December because for me it’s impossible to work, take care of life stuff and also spend several hours programming these puzzles every day 😅I normally finish around 27th or 28th December. This year I was moving to a new apartment in the middle of December, and since that wasn’t stressful enough, I took on a new challenge with Advent of Code and finished just this Sunday: doing a polyglot version, that is, every day in a different programming language! I was inspired by a friend who had done this in 2018. I thought I’d give up, but the more I solved, the more invested I was and the less willing to give up!
Every year there’s some sort of made up assembly code that you have to write an interpreter for, and then it reappears in subsequent problems, so you reuse your code, enhance it, etc. In the past, there had been a handful of problems using this assembly language. This year, however, 12 problems involved Intcode programs (the name of 2019’s made up assembly). Doing a polyglot challenge meant I had to rewrite the interpreter every time. I almost go mad 😆- hysterical laughter.
A very important part of the challenge for me was trying to write code as good as possible, even for languages I had never seen. I didn’t want to complete problems by learning how to declare variables, loops and if-else and force my Ruby or Elixir solution into the language. This meant looking at style guides so I could follow the naming conventions and that, but also getting familiar with idioms and structures, and looking at official repos and examples if possible, so my code was at least a little idiomatic. This took a lot of time in some cases, and I’m not sure I achieved my goals, but I did my best! What I didn’t do was to learn and use some features from some languages as I couldn’t really fit them in this kind of problems (like macros to manipulate AST nodes in Crystal or Nim, concurrency stuff in Erlang…).
Some fun things I learnt and other anecdotes from doing this challenge:
Programming languages with array indexes starting at 1 are stressful. In my case, this was Lua, R and Julia. Off-by-one errors are twice as fun here.
Rust is as cool as I had imagined it to be, but it has this complex and interesting memory management system that I only scratched the surface of. Ownership, borrowing and memory safety. Errors were ridiculously cryptic if you didn’t understand this very well, and yes, the hour I spent looking into it wasn’t enough to understand it well.
I always forget how much I like Golang and this made me remember. It’s so neat ❤️
Erlang was such a nice surprise. I had never used it and had this unfounded idea it was tough and unpleasant. It’s not, it’s lovely! 💘 This must be a false rumour spread by Erlang programmers so they can remain in their exclusive club.
Julia was also a nice surprise, easy to pick up, at least for the basics, and I imagined it being pretty good for scientists.
I also remembered how much I love C, it was the first language I learnt. I’m lucky I don’t write C code professionally, though. It’s seriously scary. One obscure, edge error and someone will get root in your machine.
I used Kotlin and Swift too soon for too simple problems! Same for Common Lisp and Prolog. I wasted them when I still thought I wouldn’t finish the challenge.
I skipped PHP and Java! Two languages I know and have even used professionally, but dislike them so much that I preferred to learn new ones! There’s already been enough PHP and Java in my life.
Nim was a language I didn’t even know it existed, and I’m quite glad I chose it.
Crystal’s syntax is so similar to Ruby that I felt I was cheating by using it in the challenge. Still, I made the rules, so…🤷🏻♀️
Dylan was impossible to find documentation and examples for, in the regular ways programmers search for stuff nowadays, at least. Whenever I’d google how to do something, all I’d find was someone named Dylan explaining how to do whatever I wanted to do in another language like Java. I ended up using a really good book from the 90s that I found available online in PDF.
Naming conventions in R are famously anarchic! 5 naming conventions to choose from, and multiple conventions used simultaneously in the same packages, style guides and tutorials 🤣In my code I went for the period.separated one: e.g. cut.cardssimply because I wasn’t going to have the chance of using this convention in any other language. Of course, I threw in some naming inconsistencies as well to comply with the chaos! ✌️
I hope you enjoyed reading this. If you’re interested, here are all my solutions for 2019 and the previous years. I’ll be forever grateful to Eric Wastl for creating Advent of Code, and I’m sure many other programmers share this gratitude. Now I need to think of a new challenge for next year!
A few days ago my wife and I went to see Uncut Gems at a Regal theater in Chicago.
We booked our ticket online, reserved our seats, showed up 15 minutes ahead of time, and settled in.
After the coil of previews, and jaunty, animated ads for sugary snacks, the movie started.
About 20 minutes in, a loud, irritating buzzing started coming from one corner of the theater. No one was sure what to make of it. Was it part of the movie? We all just let it go.
But it didn’t stop. Something was wrong with the audio. It was dark, so you couldn’t see, but you could sense people wondering what happens now. Was someone from the theater company going to come in? Did they even know? Is there anyone up in the booth watching? Did we have to get someone?
We sent a search party. A few people stood up and walked out to go get help. The empty hallways were cavernous, no one in sight.
Eventually someone found someone from the staff to report the issue. Then they came back into the theater to settle in and keep watching the movie.
No one from the theater came into the theater to explain what was going on. The sound continued for about 10 more minutes until the screen abruptly went black. Nothingness. At least the sound was gone.
Again, no one from the theater company came in to say what was going on. We were all on our own.
The nervous, respectfully quiet giggle chatter started. Now what?
A few minutes later, the movie started again. From the beginning. No warning. Were they going to jump forward to right before they cut it off? Or were we going to have to watch the same 25 minutes again?
No one from the theater company appeared, no one said anything. The cost of the ticket apparently doesn’t include being in the loop.
Eventually people started walking out. My wife and I included.
As we walked out into the bright hallway, we squinted and noticed a small congregation of people way at the end of the hall. It felt like finally spotting land after having been at sea for awhile
We walked up. There were about eight of us, and two of them. They worked here. We asked what was going on, they didn’t know. They didn’t know how to fix the sound, there was no technical staff on duty, and all they could think of was to restart that movie to see if that fixed it.
We asked if they were planning on telling the people in the theater what was going on. It never occurred to them. They dealt with movies, they didn’t deal with people.
We asked for a refund. They pointed us to the box office. We went there and asked for a refund. The guy told us no problem, but he didn’t have the power to do that. So he called for a manager. The call echoed. Everyone looked around.
Finally a manager came over. We asked for a refund, he said he could do that. We told him we purchased the tickets through Fandango, which complicated things. Dozens of people lined up behind us. The refund process took a few minutes.
Never a sorry from anyone. Never even an acknowledgment that what happened wasn’t supposed to happen. Not even a comforting “gosh, that’s never happened before” lie. It was all purely transactional. From the tickets themselves, to the problem at hand, to the refund process. Humanity nowhere.
We left feeling sorry for the whole thing. The people who worked at the theater weren’t trained to know how to deal with the problem. They probably weren’t empowered to do anything about it anyway. The technical staff apparently doesn’t work on the premises. The guy at the box office wanted to help, but wasn’t granted the power to do anything. And the manager, who was last in the line of misery, to have to manually, and slowly, process dozens of refunds on his own. No smiles entered the picture.
This is the future, I’m afraid. A future that plans on everything going right so no one has to think about what happens when things go wrong. Because computers don’t make mistakes. An automated future where no one actually knows how things work. A future where people are so far removed from the process that they stand around powerless, unable to take the reigns. A future where people don’t remember how to help one another in person. A future where corporations are so obsessed with efficiency, that it doesn’t make sense to staff a theater with technical help because things only go wrong sometimes. A future with a friendlier past.
I even imagine an executive somewhere looking down on the situation saying “That was well handled. Something went wrong, people told us, someone tried to restart it, it didn’t work. People got their refunds. What’s the problem?” If you don’t know, you’ll never know.
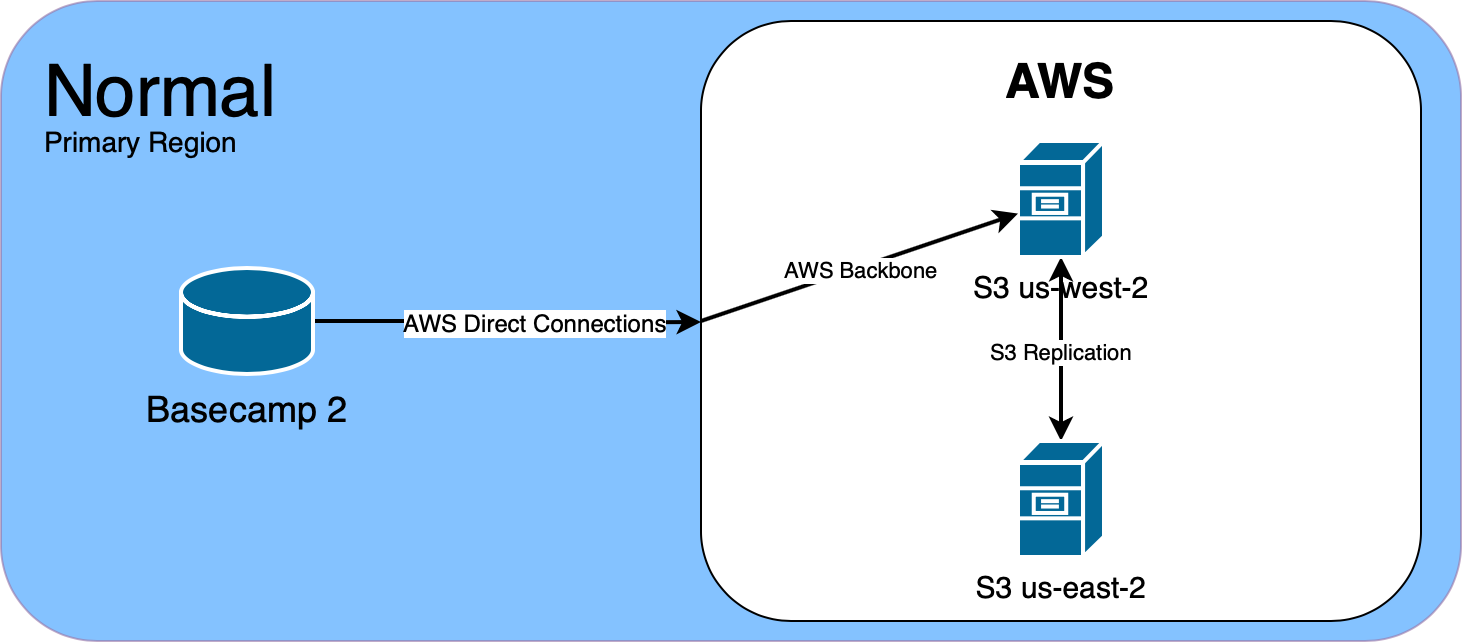
Back in November, we noticed something odd happening with large uploads to Amazon S3. Uploads would pause for 10 seconds at a time and then resume. It had us baffled. When we started to dig, what we found left us with more questions than answers about S3 and AWS networking.
We use Amazon S3 for file storage. Each Basecamp product stores files in a primary region, which is replicated to a secondary region. This ensures that if any AWS region becomes unavailable, we can switch to the other region, with little impact to users uploading and downloading files.
Back in November, we started to notice some really long latencies when uploading large files to S3 in us-west-2, Basecamp 2’s primary S3 region. When uploading files over 100MB, we use S3’s multipart API to upload the file in multiple 5MB segments. These uploads normally take a few seconds at most. But we saw segments take 40 to 60 seconds to upload. There were no retries logged, and eventually the file would be uploaded successfully.
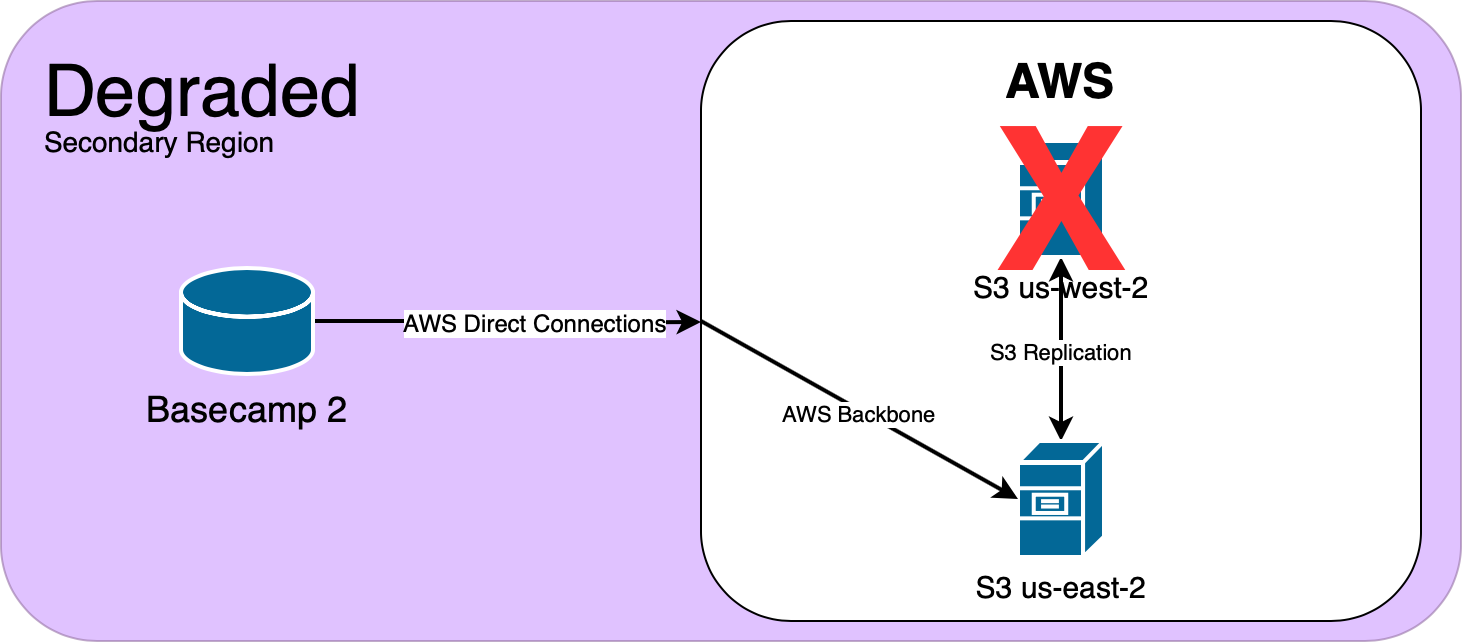
For our applications that run on-premise in our Ashburn, VA datacenter, we push all S3 traffic over redundant 10GB Amazon Direct Connects. For our Chicago, IL datacenter, we push S3 over public internet. To our surprise, when testing uploads from our Chicago datacenter, we didn’t see any increased upload time. Since we only saw horrible upload times going to us-west-2, and not our secondary region in us-east-2, we made the decision to temporarily promote us-east-2 to our primary region.
Now that we were using S3 in us-east-2, our users were no longer feeling the pain of high upload time. But we still needed to get to the bottom of this, so we opened a support case.
Our initial indication was that our direct connections were causing slowness when pushing uploads to S3. However, after testing with mtr, we were able to rule out direct connect packet loss and latency as the culprit. As AWS escalated our case internally, we started to analyze the TCP exchanges while we upload files to S3.
The first thing we needed was a repeatable and easy way to upload files to S3. Taking the time to build and set up proper tooling when diagnosing an issue really pays off in the long run. In this case, we built a simple tool that uses the same Ruby libraries as our production applications. This ensured that our testing would be as close to production as possible. It also included support for multiple S3 regions and benchmarking for the actual uploads. Just as we expected, uploads to both us-west regions were slow.
irb(main):023:0> S3Monitor.benchmark_upload_all_regions_via_ruby(200000000)
region user system total real
us-east-1: 1.894525 0.232932 2.127457 ( 3.220910)
us-east-2: 1.801710 0.271458 2.073168 ( 13.369083)
us-west-1: 1.807547 0.270757 2.078304 ( 98.301068)
us-west-2: 1.849375 0.258619 2.107994 (130.012703)
While we were running these upload tests, we used tcpdump to output the TCP traffic so we could read it with Wireshark and TShark.
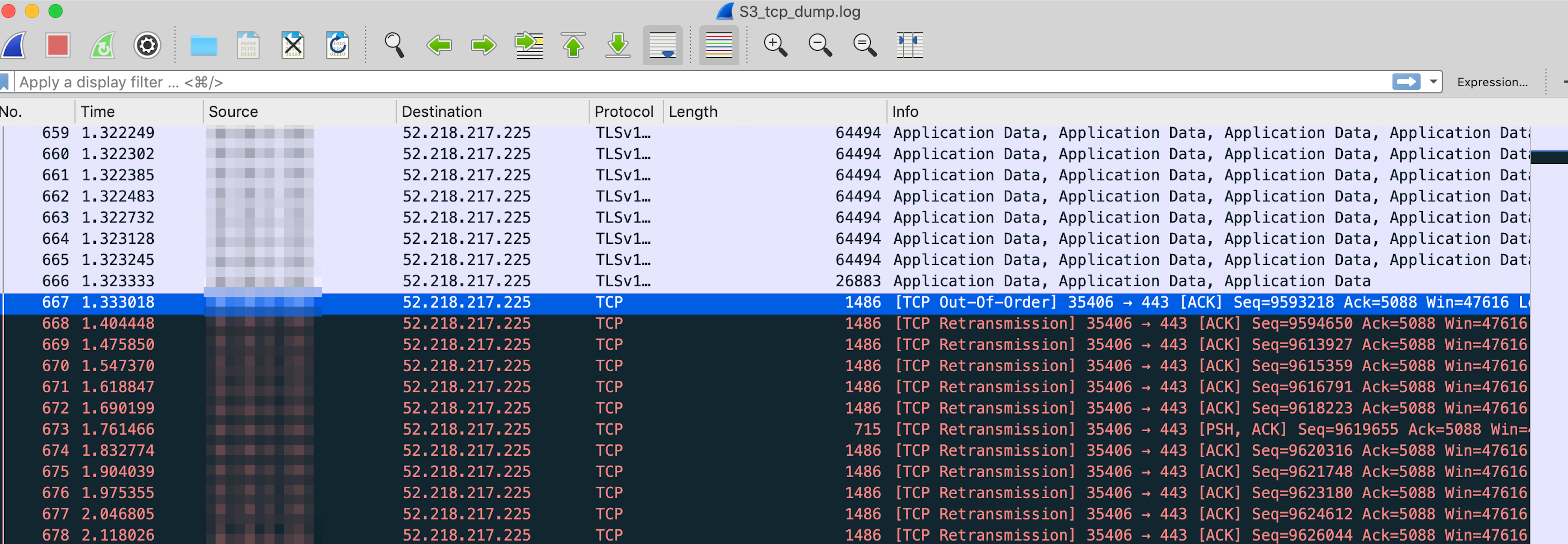
When analyzing the tcpdump using Wireshark, we found something very interesting: TCP retransmissions. Now we were getting somewhere!
TCP Retransmissions
Analysis with TShark gave us the full story of why we were seeing so many retransmissions. During the transfer of 200MB to S3, we would see thousands of out-of-order packets, causing thousands of retransmissions. Even though we were seeing out-of-order packets to all US S3 regions, these retransmissions compounded with the increased round trip time to the us-west regions is why they were so much worse than the us-east regions.
What’s interesting here is that we see thousands of our-of-order packets when transversing our direct connections. However, when going over the public internet, there are no retransmissions or out-of-order packets. When we brought these findings to AWS support, their internal teams reported back that “out-of-order packets are not a bug or some issue with AWS Networking. In general, the out-of-order packets are common in any network.” It was clear to us that out-of-order packets were something we’d have to deal with if we were going to continue to use S3 over our direct connections.
“You’re out of order! You’re out of order! This whole network is out of order!”
Thankfully, TCP has tools for better handling of dropped or out-of-order packets. Selective Acknowledgement (SACK) is a TCP feature that allows a receiver to acknowledge non-consecutive data. Then the sender can retransmit only missing packets, not the out-of-order packets. SACK is nothing new and is enabled on all modern operating systems. I didn’t have to look far until I found why SACK was disabled on all of our hosts. Back in June, the details of SACK Panic were released. It was a group of vulnerabilities that allowed for a remotely triggered denial-of-service or kernel panic to occur on Linux and FreeBSD systems.
In testing, the benefits of enabling SACK were immediately apparent. The out-of-order packets still exist, but they did not cause a cascade of retransmissions. Our upload time to us-west-2 was more than 22 times faster than with SACK disabled. This is exactly what we needed!
irb(main):023:0> S3Monitor.benchmark_upload_all_regions_via_ruby(200000000)
region user system total real
us-east-1: 1.837095 0.315635 2.152730 ( 2.734997)
us-east-2: 1.800079 0.269220 2.069299 ( 3.834752)
us-west-1: 1.812679 0.274270 2.086949 ( 5.612054)
us-west-2: 1.862457 0.186364 2.048821 ( 5.679409)
The solution would not just be as simple as just re-enabling SACK. The majority of our hosts were on new-enough kernels that had the SACK Panic patch in place. But we had a few hosts that could not upgrade and were running vulnerable kernel versions. Our solution was to use iptables to block connections with a low MSS value. This block allowed for SACK to be enabled while still blocking the attack.
$ iptables -A INPUT -p tcp -m tcpmss --mss 1:500 -j DROP
After almost a month of back-and-forth with AWS support, we did not get any indication why packets from S3 are horribly out of order. But thanks to our own detective work, some helpful tools, and SACK, we were able to address the problem ourselves.
Can you believe we used to willingly tell Google about every single visitor to basecamp.com by way of Google Analytics? Letting them collect every last byte of information possible through the spying eye of their tracking pixel. Ugh.
But 2020 isn’t 2010. Our naiveté around data, who captures it, and what they do with it has collectively been brought to shame. Most people now sit with basic understanding that using the internet leaves behind a data trail, and quite a few people have begun to question just how deep that trail should be, and who should have the right to follow it.
In this new world, it feels like an obligation to make sure we’re not aiding and abetting those who seek to exploit our data. Those who hoard every little clue in order to piece of together a puzzle that’ll ultimately reveal all our weakest points and moments, then sell that picture to the highest bidder.
The internet needs to know less about us, not more. Just because it’s possible to track someone doesn’t mean we should.
That’s the ethos we’re trying to live at Basecamp. It’s not a straight path. Two decades of just doing as you did takes a while to unwind. But we’re here for that work.
We just published “The Basecamp Guide to Internal Communication“. It’s a collection of philosophies and day-to-day practices that help guide the way we communicate with each other at Basecamp.
We cover when to write stuff up in detail vs. when to chat about it. Why meetings are a last resort, not a first option. How companies don’t have communication problems, they have miscommunication problems. Why a single central source of truth is better than different versions all over the place. Why writing benefits everyone, but speaking only benefits those who were there.
I’ve heard this one before. I’ve used this one before.
“No one’s complaining” so it fine.
“No one” really means “no one has complained to you“. It doesn’t mean no one is complaining to someone else, somewhere else.
In fact, if the thing you make/sell isn’t meeting someone’s expectations, there’s a good chance you’re the last one who’d hear the complaint.
Contacting the company to complain is pretty far down the list. At the top are friends, family, colleagues. If you aren’t hearing the complaint it’s likely because it’s directed elsewhere. People typically talk truth behind backs, not to faces.
Reputation erodes in the shadows before it comes to light.
It’s not all that different from a manager or CEO eventually discovering something was wrong but “no one told me sooner”. The higher up you are, you’re often the last to know.
Out of everywhere someone will complain, you’re close to nowhere.
“I haven’t heard anyone complain about that to me” is a more accurate statement.
So next time you say “no one’s complaining” you may be right, but you’re probably wrong. Doesn’t mean you need to do anything about it – not all complaints are worth acting on – but it should serve as a reminder that there’s a lot you don’t know.
Back in October, we announced our own two-factor authentication solution, dropping the requirement for having a Google account to benefit from this necessary level of protection for your account. This solution is based on TOTP (Time-based One Time Password Algorithm): you configure a special authenticator app with a secret we provide and then your app generates codes depending on the time that we can verify on our side after you have entered your credentials, as the second step before login you in.
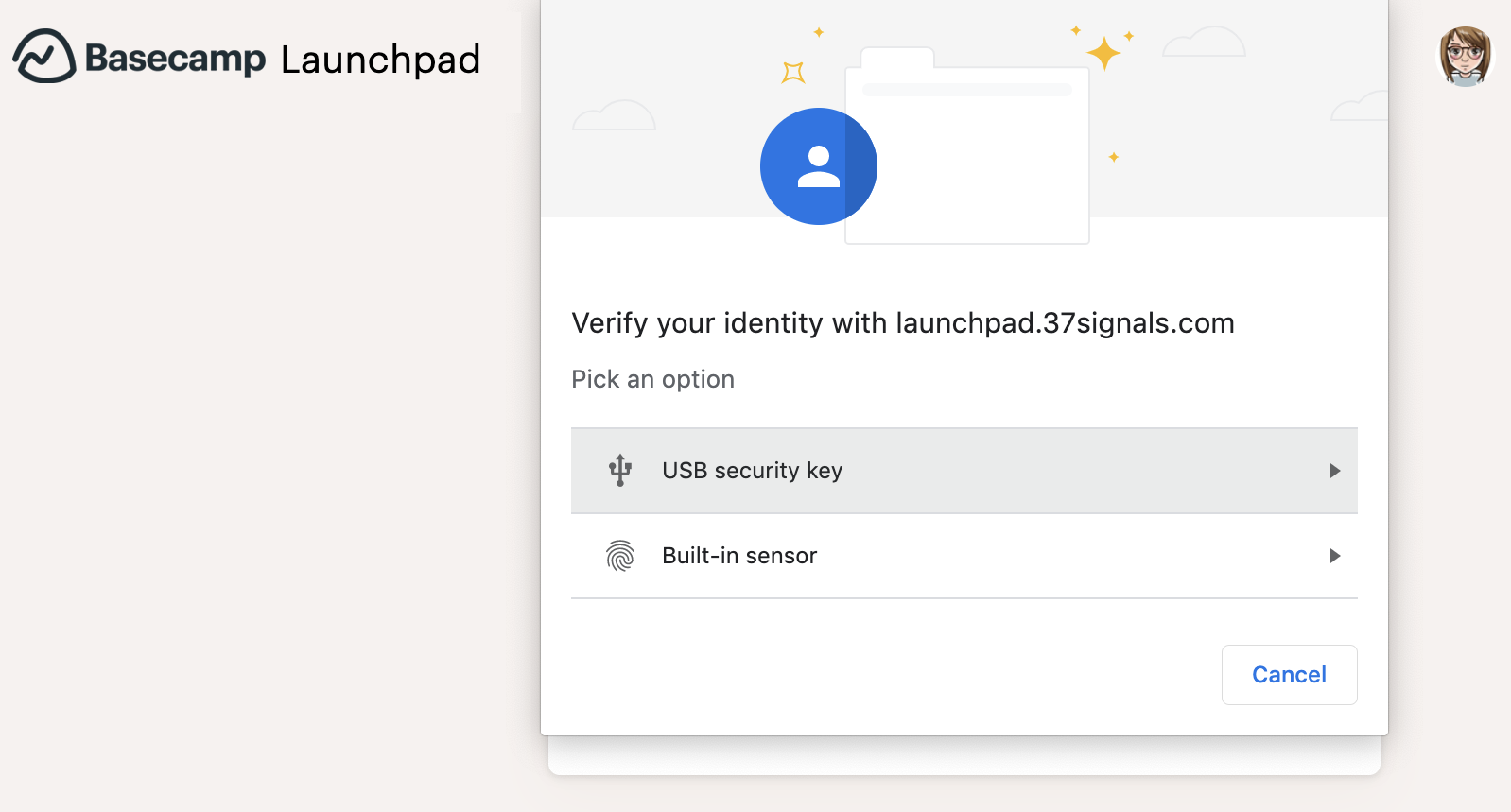
This kind of second-factor authentication is very convenient and easy to use, but it has weaknesses. A sophisticated phishing page could trick you into entering your username and password and then your second-factor code and use it right away to log in into your Basecamp account. This is where FIDO2: Web Authentication (WebAuthn) comes in. I’m happy to announce we now support WebAuthn for security keys and other authenticators as an alternative 2FA method. WebAuthn is the newer standard for secure authentication on the web and is more widely adopted and supported by browsers and authenticators than its predecessor, U2F.
With WebAuthn we can offer a 2FA method resilient to fancy phishing attacks because authentication relies on public-key cryptography to prove to Basecamp that it’s indeed you who is logging in, and this proof only works for https://launchpad.37signals.com/ and not for a fake phishing page that copies perfectly our own Launchpad.
Mobile: Chrome for Android 78, Firefox for Android 68, Safari for iOS 13.3
Another cool aspect of WebAuthn is that it opens the door to new kinds of authentication devices and you no longer need to own special hardware keys. You’ll be able to use your phone or laptop and authenticate with a PIN, or use a fingerprint reader or facial recognition. For example, you can use your Android phone’s fingerprint reader in Chrome, Apple’s Touch ID in Chrome for macOS, and facial recognition, fingerprint reader or PIN via Windows Hello in Edge. Of course, you can also use specific security keys like Yubico’s YubiKeys, which is what I use. Older keys based on the U2F standard work too as WebAuthn is backwards compatible with U2F authenticators, so if you have one of these, you can register it in your Basecamp account as well.
Read more about how to register your security keys and start using this as your second-factor step for your Basecamp account, and, if you haven’t already, please, please enable 2FA for your Basecamp account now.
🔐👩🏻💻Implementing WebAuthn and 2FA for your own application
Providing your users with modern authentication mechanisms is a reasonably easy task thanks to a variety of open-source libraries in multiple languages. For WebAuthn, we relied on the excellent webauthn-ruby by Cedarcode. They also have a great Rails demo app to show how to use this gem. I encourage checking this out if you want to support WebAuthn in your Rails app, it’s super useful. For the client-side code, we ended up using the webauthn-json wrapper by GitHub that handles all encoding, decoding and building the different JSON objects.
We’ve got questions by some people about how we implemented our 2FA solution based on TOTP, and this is also fairly easy! We again took advantage of an open-source gem, rotp by Mark Percival, although initially, we had implemented the algorithm described in the RFC for HOTP and the TOTP extension. It’s simple and totally doable if you prefer not to use an external library. If you do this, I recommend testing your implementation using the provided test vectors. We’ve also followed the security considerations detailed in the RFC:
We store secrets for TOTP (and recovery codes) encrypted using AES-256-GCM.
To account for time drift between the server and clients and transmission delays, we accept one code generated in the time window before and after the current one and use the recommended time-step size of 30 seconds.
We need to ensure a one-time only use of a code, which means we can’t accept the second and subsequent submissions of a code within the same time window. We use Redis to “quarantine” a valid code after it’s been accepted and take advantage of its key expiration mechanisms,
We spend about $3 million every year to run all the versions of Basecamp and our legacy applications. That spend is spread across several on-premise data centers and cloud operations. It does not include the budget for our 7-person strong operations team, this is just the cost of connectivity, machines, power, and such.
There’s a lot of spend in that bucket. The biggest line item is the million dollars per year we spend storing 4.5 petabyte worth of files. We used to store these files ourselves, across three physical data centers for redundancy and availability, but the final math and operational hassle didn’t pan out. So now we’re just on S3 with a multi-region redundancy setup.
After that, it’s really a big mixed bag. We spend a lot of money on databases, which all run on MySQL. There’s ElasticSearch clusters that power our search. A swarm of Redis servers providing caching. There’s a Kafka pipeline and a Big Query backend for analytics. We have our own direct network connections between the data centers and the cloud.
Everything I’ve talked about so far is infrastructure we’d run and pay for regardless of our programming language or web framework. Whether we run on Python, PHP, Rust, Go, C++, or whatever, we’d still need databases, we’d still need search, we’d still need to store files.
So let’s talk about what we spend on our programming language and web framework. It’s about 15%. That’s the price for all our app and job servers. The machines that actually run Ruby on Rails. So against a $3 million budget, it’s about $450,000. That’s it.
Let’s imagine that there was some amazing technology that would let us do everything we’re doing with Ruby on Rails, but it was TWICE AS FAST! That would save us about ~$225,000 per year. We spend more money than that on the Xmas gift we give employees at Basecamp every year. And that’s if you could truly go twice as fast, and thus require half the machines, which is not an easy thing to do, despite what microbenchmarks might delude you into thinking.
Now imagine we found a true silver bullet. One where the compute spend could be reduced by an order of magnitude. So we’d save about $400,000/year, reducing everything we spend running our app and job servers to an unrealistically low $45,000/year. That reduction wouldn’t even pay for two developers at our average all-in cost at Basecamp!
Now let’s consider the cost of those savings. We spend more money on the 15-strong developer team at Basecamp than our entire operations budget! If we make that team just 15% less productive, it’ll cost us more than everything we spend to run Ruby and Rails at Basecamp!
Working with Ruby and Rails is a luxury, yes. Not every company pay their developers as well as we do at Basecamp, so maybe the rates would look a little different there. Maybe some companies are far more compute intensive to run their apps. But for most SaaS companies, they’re in exactly the same ballpark as we are. The slice of the total operations budget spent running the programming language and web framework that powers the app is a small minority of the overall cost.
For a company like Basecamp, you’d be mad to make your choice of programming language and web framework on anything but a determination of what’ll make your programmers the most motivated, happy, and productive. Whatever the cost, it’s worth it. It’s worth it on a pure cost/benefit, but, more importantly, it’s worth it in terms of human happiness and potential.
This is why we run Ruby. This is why we run Rails. It’s a complete bargain.