Since we started working on HEY, one of the things that I’ve been a big proponent of was keeping as much of the app-side compute infrastructure on spot instances as possible (front-end and async job processing; excluding the database, Redis, and Elasticsearch). Coming out of our first two weeks running the app with a real production traffic load, we’re sitting at ~90% of our compute running on spot instances.
Especially around the launch of a new product, you typically don’t know what traffic and load levels are going to look like, making purchases of reserved instances or savings plans a risky proposition. Spot instances give us the ability to get the compute we need at an even deeper discount than a 1-year RI or savings plan rate would, without the same commitment. Combine the price with seamless integration with auto-scaling groups and it makes them a no-brainer for most of our workloads.
The big catch with spot instances? AWS can take them back from you with a two-minute notice.
Spot-appropriate workloads
Opting to run the bulk of your workloads on spot only works well if those workloads can handle being torn down and recreated with ease (in our case, via Kubernetes pods). What does “with ease” mean though? For us it means without causing exceptions (either customer-facing or internally) or job failures.
For HEY, we are able to get away with running the entire front-end stack (OpenResty, Puma) and the bulk of our async background jobs (Resque) on spot.
Enduring workloads
What doesn’t fit well on spot instances? For HEY, we’ve found three main categories: long-running jobs, Redis instances for branch deploys, and anything requiring a persistent volume (like certain pieces of the mail pipeline). We put these special cases on what we refer to as the “enduring” nodegroup that uses regular, on-demand instances (and probably RIs or savings plans in the future).
Let’s take a look at each:
- Jobs that have the possibility of running for more than a minute-and-a-half to two-minutes are an automatic push over to the enduring node-group. Currently for HEY this is just account exports.
- Redis is a primary infrastructure component for HEY. We use it for a bunch of things — view caching, Resque, inbound mail pipeline info storage, etc. HEY has a dynamic branch deploy system that deploys any branch in GitHub to a unique hostname, with each of those branch deploys needing their own Redis instances so that they don’t step on each other (using the Redis databases feature doesn’t quite work here). For a while we tried running these Redis instances on spot, but ugh, the monitoring noise and random breakage from Redis pods coming and going and then the app connecting to the read-only pod and throwing exceptions…. it was too much. The fix: get them off of spot instances. [this only affects beta/staging — those environments use a vendored Redis Helm chart that we run in the cluster, production uses Elasticache]
- We’ve successfully run lots of things that require PVCs in Kubernetes. Heck, for several months we ran the entire Elasticsearch clusters for Basecamp 2 and 3 on Kubernetes without any major issues. But that doesn’t mean I’d recommend it, and I especially do not recommend it when using spot instances. One recurring issue we saw was that a node with a pod using a PVC would get reclaimed and that pod would not have a node to launch on in the same AZ as the existing PVC. Kubernetes
absolutely loves thisshows this via a volume affinity error and it frequently required manual clean-up to get the pods launching again. Rolling the dice on having to intervene whenever a spot reclamation happens it not worth it to our team.
Getting it right
node-termination-handler
Arguably the most important piece of the spot-with-Kubernetes puzzle is aws-node-termination-handler. It runs as a DaemonSet and continuously watches the EC2 metadata service to see if the current node has been issued any spot termination notifications (or scheduled maintenance notifications). If one is found, it’ll (attempt to) gracefully remove the running pods so that Kubernetes can schedule them elsewhere with no user impact.
cluster-autoscaler
cluster-autoscaler doesn’t need many changes to run with a spot auto-scaling group. Since we’re talking about ensuring that instance termination behaviors are handled appropriately though, you should know about the pain we went through to get ASG rebalancing handled properly. When rebalancing, we’d see nodes that just died and the ALB would continue to send traffic to them via kube-proxy because there was no warning to kubelet that they were about to go away. aws-node-termination-handler cannot handle rebalancing currently, but I believe that EKS managed nodegroups do — at the expense of not supporting spot instances. A project called lifecycle-manager proved to be critical for us in handling rebalancing with ease (even though we ended up just disabling rebalancing all together 😬).
Instance types and sizes
It’s wise to do your own testing and determine how your workloads consume CPU and memory resources and choose your EC2 instance types and sizes accordingly. Spot ASGs are most valuable when the ASG scheduler can pick from many different instance types and sizes to fill your spot requests. Without spreading that load across many types (or sizes), you run the risk of being impacted by capacity events where AWS cannot fulfill your spot request.
In fact, we had this happen to us earlier in the year when spot demand skyrocketed. We ran into issues with the ASG telling us there was no spot capacity to fulfill our request, and when things were fulfilled, it wasn’t uncommon for those instances to be reclaimed just a few minutes later. The churn was untenable at that rate. The fix for us was to run with other instance types and sizes.
Our workloads perform best with C-series instances, we know this, so that’s what we use. However, if you can get away with using M or T-series instances, do it (they have comparable CPU/memory requests across the size range and you easily pull from m5, m5d, m5n, etc. to add more variability to your spot requests).
A gotcha: cluster-autoscaler really does not like mixed-instance ASGs where the CPU and memory requests are not the same across the available node types. It can leave you in a position where it thinks the ASG has 8c/16g nodes while the ASG actually fulfilled a request using a 4c/8g node — now cluster-autoscaler’s math on how many instances it needs for the set of unschedulable pods is incorrect. There’s a section on this in the cluster-autoscaler documentation, but the tl;dr is that if you want to use different instance types, make sure the specs are generally the same.
Availability zones and regions
Spot instance availability and price varies a ton across availability zones and regions. Take this example of c5.2xlarge spot instances in us-east-1:
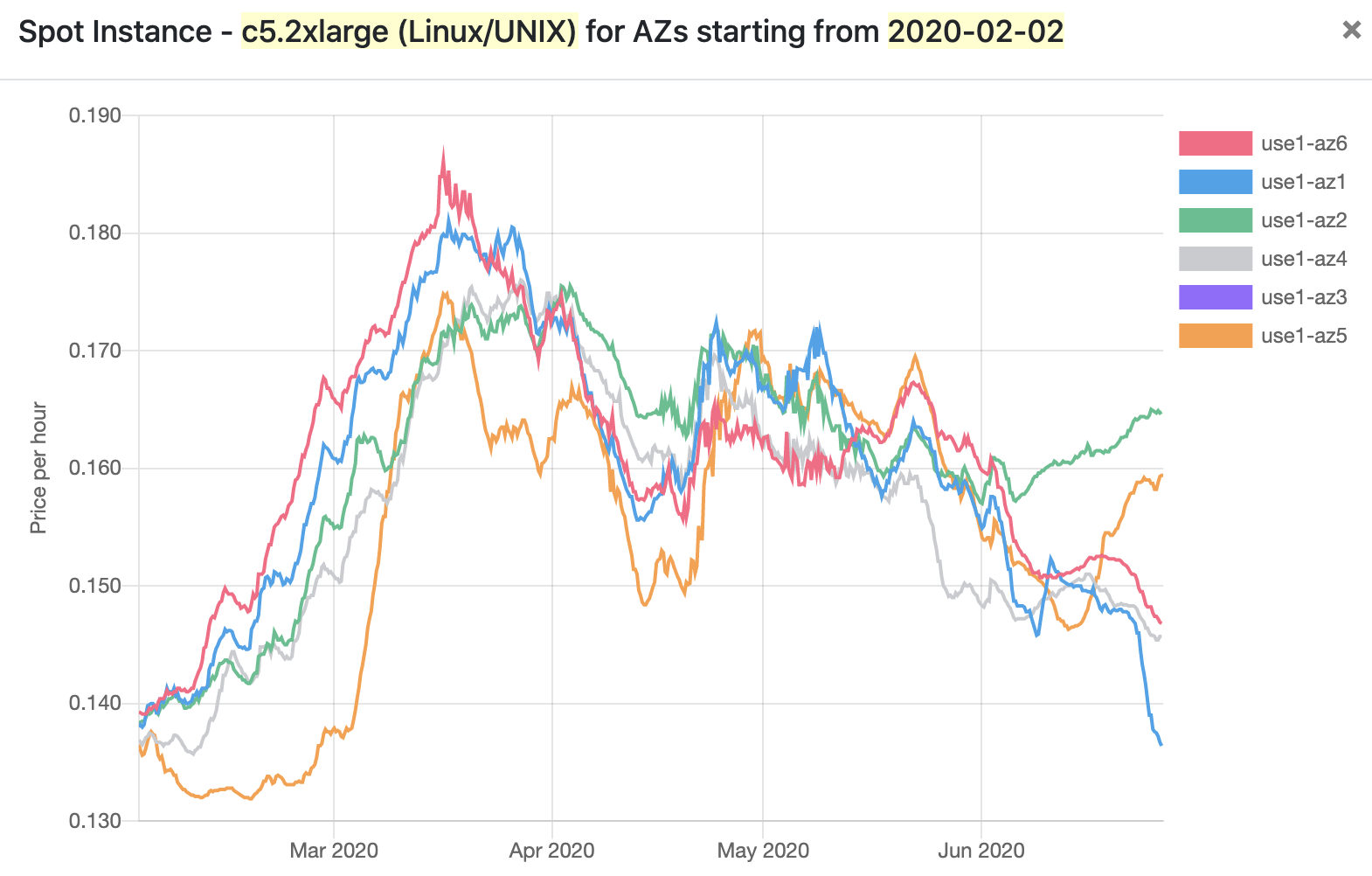
Especially since the beginning of June, there is a wild disparity in spot prices across the us-east-1 AZs! If you’re scheduling only in us1-az2, you’re paying an 18% premium over us1-az1. If your ASG is setup to span AZs, this is automatically taken into account when fulfilling spot requests and AWS will try to place your instances in cheaper AZs if possible (unless you’ve changed the scheduling priority option).
But it’s not just availability zones where there are real price disparities. Among different regions, the price differences can be even stronger. Take us-east-1 and us-east-2 — two regions where the prices of compute are typically the same for on-demand reservations. In us-east-2, spot requests for c5.2xlarge instances are currently going for between 40-50% cheaper than the same thing in us-east-1:
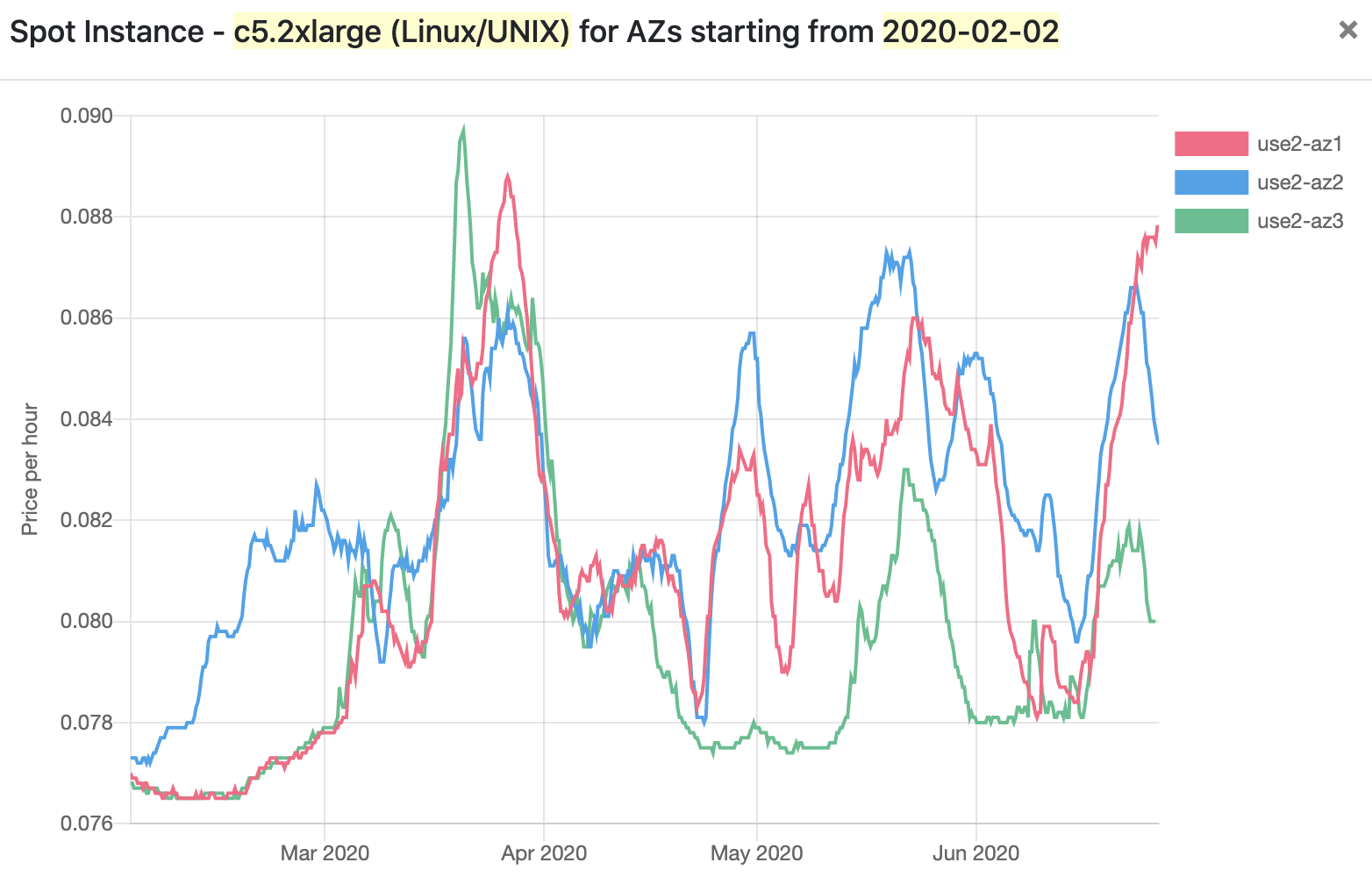
That’s a significant savings at scale. Of course there are other obligations for running in other regions — are all of the services you use supported, can you reach other infrastructure you may have, etc. (and it’s also possible that moving to another region for price alone just doesn’t make sense for you, that’s totally fine!).
Leveling up
Merely running compute on spot isn’t the end-goal though, and there are several paths that we can take to continue to level-up our compute infrastructure to place resources optimally, both from a cost standpoint and for keeping things close to the end user.
- [shorter term] Using the Horizontal Pod Autoscaler to automatically scale deployment replica counts as traffic to the platform regularly ebbs and flows. When combined with cluster-autoscaler, Kubernetes (with a lot of trust from your ops team…..) can take care of scaling your infrastructure automatically based on CPU utilization, request latency, request count, etc. HEY is already starting to show a standard traffic pattern where usage is highest during the US work hours and then drops greatly overnight and on the weekends. These are perfect times to scale the app down to a smaller deployment size. Front-end compute isn’t the biggest cost driver for HEY (that falls to persistent data storage infrastructure like Aurora and Elasticache), but scaling something down when you can is better than not scaling anything at all.
- [long term] Shunting compute between regions and AZs based on spot pricing. This is likely to not be something that a company the size of Basecamp ever needs to think about, but being able to shunt traffic around to different regions and AZs based on compute cost and availability is a dream stretch goal. This is tricky because we also need to take into account where our data backends live. Maybe you’re already running an active/active/active setup with three regions around the world and can gradually shift your scaling operations around the different regions as different parts of the world start to wake-up and use your app. Maybe you’re just using a simpler active/active setup, but compute prices or availability in region A start to show signs of trouble, you can easily move over to region B.
Conclusion
Spot instances can be a great tool for managing spend while getting the compute resources you need, but they come with additional challenges that you must remain aware of. Going down this path isn’t a one-time decision — especially with an app that is seeing active development, you have to be mindful of changing resource utilization and workflows to ensure that spot terminations don’t cause harm to your workloads and customers, and that changes in core spot features (like pricing and availability) don’t impact you.
The good news is that if spot does turn out to be a negative for you, moving to on-demand is a single change to your auto-scaling group config and then gradually relaunching your existing instances.
If you’re interested in HEY, checkout hey.com and learn about our take on email.
Blake is Senior System Administrator on Basecamp’s Operations team who spends most of his time working with Kubernetes, and AWS, in some capacity. When he’s not deep in YAML, he’s out mountain biking. If you have questions, send them over on Twitter – @t3rabytes.

This answers a bunch of questions I had about actually using spot instances. Did you do a cost analysis before embarking on this, given a budget, or did you just really want to make spit instances work out of professional pride? 🙂
How do you balance exploiting the cost disparity by zone with staying geographically distributed and keeping enough compute proximate to your customers, if that’s an issue?
I love these kind of “behind the scene tech posts”. Please keep them coming and write more!!!