
There are only two hard things in Computer Science: cache invalidation and naming things — Phil Karlton
Doing cache invalidation by hand is an incredibly frustrating and error-prone process. You’re very likely to forget a spot and let stale data get served. That’s enough to turn most people off russian-doll caching structures, like the one we’re using for Basecamp Next.
Thankfully there’s a better way. A much better way. It’s called key-based cache expiration and it works like this:
- The cache key is the fluid part and the cache content is the fixed part. A given key should always return the same content. You never update the content after it’s been written and you never try to expire it either.
- The key is calculated in lock-step with the object that’s represented in the content. This is commonly done by making a timestamp part of the key, so for example [class]/[id]-[timestamp], like todos/5-20110218104500 or projects/15-20110218104500, which is what Active Record in Rails does by default when you call #cache_key.
- When the key changes, you simply write the new content to this new key. So if you update the todo, the key changes from todos/5-20110218104500 to todos/5-20110218105545, and thus the new content is written based on the updated object.
- This generates a lot of cache garbage. Once we’ve updated the todo, the old cache will never get read again. The beauty of that system is that you just don’t care. Memcached will automatically evict the oldest keys first when it runs out of space. It can do this because it keeps track of when everything was last read.
- You deal with dependency structures by tying the model objects together on updates. So if you change a todo that belongs to a todolist that belongs to a project, you update the updated_at timestamp on every part of the chain, which will automatically then update the cache keys based on these objects. In Rails, you can declare it like this:
- The caching itself then happens in the views based on partials rendering the objects in question. This can be neatly nested like below where each call to
cachewill call #cache_key on the elements of the passed-in array. So in the first case, the cache key ends up being something like v5/projects/5-20110219102600. That key is then updated when the object is updated as described in the process above, and the proper cache is always fetched.
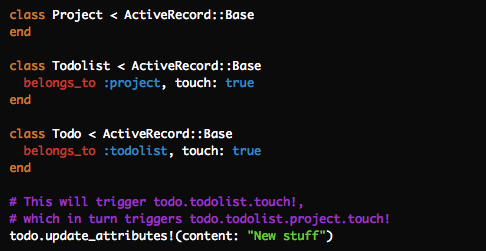
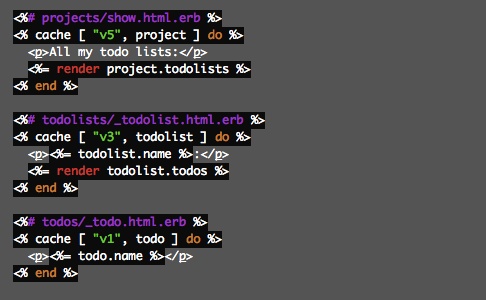
This process makes it trivial to implement caching schemes and trust that you’re never going to serve stale data. There’s no messy cleanup to deal with since you’re not obligated to track down every spot that might update an object. The updated_at field that’s part of all the caching keys automatically takes care of that for you, wherever that update came from.
Xavier Noria
on 19 Feb 12Just for the record, if you are using Redis as cache store with default settings, then you need to mark these keys as volatile so that Redis know it can get rid of them. See details in http://antirez.com/post/redis-as-LRU-cache.html.
Justin Ko
on 19 Feb 12Could you use “touch” to be more semantic?
todo.update_attributes(content: “New stuff”).touch
DHH
on 19 Feb 12Justin, my bad, left a stray save in there. #update_attributes already calls save and saving is all you need to trigger the touching chain.
Denis
on 19 Feb 12Do these v1, v3 and v5 represent the versions of the partials? And you will update v1 to v2 when todo partial markup changes for example.
DHH
on 19 Feb 12Denis, exactly. You bump the version when you change what goes into the cache (either from a change in the partial, the model, or a helper used to generate the content).
Justin Ko
on 19 Feb 12DHH, oh God and even my example code is wrong! LOL – “update_attributes” will return true. Can we delete both our comments and act like this never happened? ;)
Ustun Ozgur
on 19 Feb 12When do you generate the new html content exactly? When the object is saved, or when the keys are first requested?
You seem to say the former, so how do you know which keys belong to an object, that is, if there are more than one html snippets which depend on the object?
DHH
on 19 Feb 12The cache is generated on the first request. In the code blocks in step 6, we’ll run what’s inside the block if there’s no cache content for the cache key generated by the parameters we pass to #cache. After the first run, that content is then saved.
You can have multiple caches depend on the same object by mentioning that object in multiple cache keys. When you update the object, every cache key that depends on that object is bumped and they all have to regenerate their content.
Ustun Ozgur
on 19 Feb 12@DHH What about some predictive (preemptive) caching? Would that work at all?
I’m thinking something along the lines: If a user visits the site very frequently, add him to the list of people whose pages will be pre-generated etc.
stjernstrom
on 19 Feb 12I really like this. Seems like the key is:
“The cache key is the fluid part and the cache content”
Koz
on 19 Feb 12The more common name for this caching strategy is generational caching and it’s definitely easier. Declaring the cache dependencies at the call/definition site rather than in weird observers.
One gotcha you can hit is with the way the slab allocator works in memcached. You can end up with a large amount of ram used ineffectively especially if you combine generational caches with TTL values in the same cache family.
Evan, formerly of twitter, released a fancy tool and great blog post a while back. I tracked down the initial blog post for those who might be interested.
Glen Mailer
on 19 Feb 12Is there any caching of the model methods themselves being done? While this speeds up the HTML generation hugely, it still requires you to get the relevant objects out of the DB to calculate the key, which may or may not require a complex query.
Or am I missing something?
Jamie
on 19 Feb 12This is a great write up. But it looks like ‘touch’ only works with belongs_to. What if you wanted to do it the other way around with has_many ?
For argument’s sake let’s say you had a partial showing a Todo with its parent Todolist name. If you updated the Todolist name, the cached Todo partial would be stale as Todolist can only touch its parent rather than its children. (child-touching jokes at the ready…)
Jamie
on 19 Feb 12Or a better example for my question above:
Todo belongs_to User User has_many Todo
Partial shows:
{{todo}} assigned to {{username}}
If I change my username, all the todo partials will be stale because User has_many Todo and can’t touch like belongs_to.
KTB
on 19 Feb 12Could you elaborate on how you get stuff from the cache? Ie. if I want to fetch the ToDo with the id 5, how do I get the correct cache key?
Laszlo Korte
on 19 Feb 12You could put the user object into the cache key:
<% cache [‘v1’, todo, todo.user] do %>
stjernstrom
on 19 Feb 12Would be really neat if we could get a checksum from a Proc
Eli
on 19 Feb 12Do you have any locks and if so is lock contention an issue with this scheme?
Jamie
on 19 Feb 12@Laszlo Actually that did cross my mind after I posted, but then you trigger another DB read, reducing the usefulness of the cache.
Sweam
on 19 Feb 12@Glen Mailer, exactly what I thought: this still is hitting the DB at full speed. Maybe they only cache complex queries? I’d love to hear an explantation!
Josh Goebl
on 19 Feb 12Glen Mailer: It’s not as bad as you think… if the project hasn’t changed then none of the todolists or todos have to be loaded to calculate the project cache_key… if only one todo has been changed then only the top level todo lists have to be loaded (to recache the project), and only all the todos inside a single todo list (to recache that todo list). Still a very small amount of the full dataset.
Josh Goebel
on 19 Feb 12Sweam: See my response to Glen. But in my experience on complex pages DB access is only 20-30% of the entire response time anyways… so even if ALL the db had to be loaded to determine if the cache was valid that would still be a 70-80% speed increase.
Roger campos
on 19 Feb 12Just to add my 2 cents, the expiration key based on the updated_at is precise up to the second, so it might happen that your integration tests fail due to them beeing too fast. Maybe you need to add some sleep to make sure your tests gets the new version.
Sofia Cardita
on 19 Feb 12@Glen Mailer In this scheme you stil hit the db for the top object of the chain, in this case, projects. But you could keep a cache for the project keyed by project id only, which would have the timestamp (which would also have to invalidated when the updated_at field changes in the project model). Then, just get the cache for the project by the project id, from there you get the timestamp and can fetch the rest of the cache objects.
Manuel F. Lara
on 19 Feb 12I don’t know about Ruby or Rails so maybe this is done automatically and my question is stupid, but:
If your cache is projects/15-20110218104500 for example, where do you store that timestamp? Is there another cache like projects/15-time where you always have the last timestamp for the projects list? Like you just update this cached value when something changes, and this is what triggers everything, since you use that value to construct the actual cache with the content (use that value as part of the key for the projects/15-$timestamp?
Manuel F. Lara
on 19 Feb 12In my previous comment, when I said “the last timestamp for the projects list” I meant “the last timestamp for that particular project”, since I guess “projects/15-$timestamp” is the cache block for one project, not a list of projects.
Fernando Correia
on 19 Feb 12As Evan Weaver pointed out (http://blog.evanweaver.com/2009/04/20/peeping-into-memcached/), to efficiently use the generational key technique, you should use distinct pools for the generational keys and for the direct keys.
Ed
on 19 Feb 12I could remember this whole similar caching thing being done in Twitter. But yet i couldn’t find the article from google.
tobi
on 19 Feb 12This scheme is even mostly transactionally consistent meaning reads will (mostly) see an atomic view of the word. But not always because the old version’s cache items might get partially evicted so a part of the request gets served from new data and a part from old data.
Sweam
on 19 Feb 12@Josh Goebel, I understand it a bit better now, but you agree that all the database queries are executed? If only some of them are executed I would like to know how that’s possible, because that’s outside the scope of fragment caching as far I’m aware of?
Hank
on 19 Feb 12All
Not to sound snarky, but isn’t this how everyone has always done web based caching?
Manuel F. Lara
on 19 Feb 12@Hank: not at all, there are different ways of caching. You can cache stuff for X amount of time (a few hours), you can cache things and then delete those cache keys when something gets updated, etc. Depends on the case and of the methodology you want to use.
Hank
on 19 Feb 12All
It’s important for everyone to read this post at HackerNews on this topic:
Not too many people know memcache better, and how to properly use it, than Facebook.
So if you plan to implement DHH approach, be forewarned that even his approach “doesn’t solve all possible cache consistency problems”.
DHH
on 19 Feb 12Hank, correct. If you are Facebook scale, you need to deal with problems the rest of us will rarely ever see (like cross data center race conditions). Good thing that they have smart and capable people working on those problems. For the rest of us, we can be happy to use what’s available today.
Stefan
on 19 Feb 12What is the advantage of having the key change instead of the content?
How do you know what is the new key once it changes?
Hank
on 19 Feb 12@DHH
No, that’s not what he/she is saying.
I obviously can’t speak on behalf of the HackerNews/Facebook-employee but the takeaway I learned from his/her comment was that if your caching solution is distributed over more than a single cache server, which yours is – the implementation approach you have designed and outlined in this post is flawed.
Ryan Sharp
on 19 Feb 12http://plan9.bell-labs.com/sys/doc/venti/venti.html
Ryan
on 19 Feb 12@Hank
You can take your posturing elsewhere. The old “Facebook says so” cargo-cult garbage is getting quite tired now.
Facebook is just one problem that calls for the collaboration of many talented engineers. It’s not a secret society of geniuses, whose approval you can use to win arguments.
Take a nap, champ.
Hank
on 19 Feb 12@Ryan
Facebook does more active development on memcache than ANYONE ELSE.
So, like I said in my original comment, when I encountered the post on HackerNews advising against DHH implementation, I found it worthwhile to share that post.
I’m done commenting on this topic.
All I was trying to do was help point out concern raised by experts in this technology. Nothing more.
Brian Morearty
on 19 Feb 12It would be wonderful if Rails had a simple set of assertions built-in, or as a gem, to test fragment cache expectations for integration tests. I haven’t found such assertions in the wild and have thought about writing a gem with them but am putting it out there in case anyone else wants to. E.g.,
1. Get a page. 2. Get it again in a different session—assert that a fragment cache was used. 3. Modify an object that’s used in the fragment. 4. Get the page again—assert that the cache was not used.
Scott
on 19 Feb 12Brilliant in its ease and simplicity. I can’t think of a reason to continue with the traditional approach where the cache key is fixed. Thanks for sharing.
glenn
on 19 Feb 12As near as I can tell, this technique assumes that your storage system is fast ( because it has to pre-fetch the objects in order to create the keys ) and that your templates are slow ( because it is caching the results of the use of those objects ).
Is that right?
Oleh
on 19 Feb 12@DHH For me the most interesting part is bumping template version. I’m curious whether you have some automation, or manually update every time?
Not sure if it’s possible, but the idea of having git pre-commit hook for handling this seems good to me.
johno
on 19 Feb 12@DHH Hmm, if you update _todo.html.erb partial do you have to bump the version number in all views that use this partial?
JF
on 19 Feb 12For me the most interesting part is bumping template version. I’m curious whether you have some automation, or manually update every time?
Currently we have to bump the cache version number manually, which is inconvenient at times, but the gains are worth it. Down the road we’d like to automate the process, but we’ve been focused on building, not optimization, at this point. We’ll improve this down the road.
Stefan
on 19 Feb 12How do you get the right key name of an update?
Mark IJbema
on 19 Feb 12If the number of releases is small in comparison to the number of updates in the cache one could use the git revision. This would have the disadvantage that the site is temporarily slow after each release. However having some way to get a checksum from a proc would be a lot neater.
David Andersen
on 20 Feb 12The product I work with handles cache invalidation by making it almost impossible to generate a cache entry in the first place (it’s a SQL generating reporting tool). Very elegant.
Aaron Goodman
on 20 Feb 12What do you do about source code changes? Suppose you change the way that todolists are generated from todo items. How do you invalidate the appropriate cache keys?
Scott
on 20 Feb 12Aaron – you don’t invalidate the cache keys. Instead you create new keys by upping the “version” part of the cache key – e.g. ‘cache [“v1”, “todo_list”]’ gets changed to ‘cache [“v2”, “todo_list”]’.
You never invalidate keys which is the point. You solve the hardest part – key invalidation – by not performing it.
Hong
on 20 Feb 12Hey DHH,
for this case:
a Task has many Owners a Owner has many Tasks
and we have a method like this:
def get_tasks_by_owners( owner_name)
return all tasks by Owners who have Owner_name like owner_nameend
and sometimes during the day, there will be new Owners with the same name registering to the system (but we can not sure when it may happen )
Can we use this technique for the type, or what is your way to invalidate ?
Andrew
on 20 Feb 12Hong, the different owner will have different ID’s. Just include the ID in the cache key and you’re good to go.
Visa
on 20 Feb 12There’s also another version of that quote:
Hong
on 20 Feb 12@Andrew: I’m not sure if I get you right.
This is a join query.
What you mean is whenever there is new Owner, then we have to change the cache key for this query?
Or you mean that we should break this join query into 2 select queries: - the first select query will select all Owners has the query_name . Then, caching the result.
- the second select query will select all tasks based on the list of previous list of owners.
Is it a good idea if there are 100.000 owners have the same name?
Casey
on 20 Feb 12I was looking through this and the HackerNews thread and think I understand how the project is read each time from the DB and then child objects are pulled from the timestamp value of the parent project DB entry. A question though.
Given this hierarchy: project A-> list B -> todo C, wouldn’t you also have to update all siblings of todo C and list B on every change of any of them? The example only shows updating 3 objects, but seems like the timestamp on a sibling of todo C, call it todo C’, would have to be updated as well or the single-parent read would not provide enough information to retrieve the child caches. Likewise if there was a sibling list and all of it’s child todos.
If you had a large set of child objects on a project, it seems like the write inefficiencies would outweigh the read positives.
Seems like I’m missing something though, can anyone clarify?
Justin Reese
on 20 Feb 12@Casey: That’s described in more detail in DHH’s other post, but the crux is: invalidating C does require regenerating A, B, and C, but not any siblings, since the siblings still have valid caches. So C is regenerated (obviously), then B is regenerated using the fresh C plus the cached versions of C’s siblings, then A is regenerated using the fresh B plus the cached versions of B’s siblings. Make sense?
ashley
on 20 Feb 12Hi, at the risk of sounding moronic, how can I read the latest version of an object from the cache without knowing it’s latest updated_at value, which I presume I have to get from the DB?
I’m very interested in this approach for an app engine project that needs to cut down on datastore reads, it could be perfect, but if I need to hit the datastore to get the updated_at, just to get the cache key, then I’m no better off am I?
Haitham
on 20 Feb 12This has been done and formulated by the guys at eSpace a VERY LONG time ago..
check it out http://www.espace.com.eg/blog/2009/02/17/version_cache-1-2-3-its-all-in-the-numbers-/
Farsi dictionary
on 21 Feb 12Thanks for sharing the article, it’s interesting and useful.
Chris
on 21 Feb 12For those who are worried about memcached running out of memory in a specific slab pool, check out the release notes for one of the latest builds (memcached v1.4.1 Release Notes).
They’re working to implement a ‘smart’ slab algorithm that will recognize when a specific slab pool is being worked harder than other slabs. Memory will then be taken from under-utilized slab pools and given to busy slabs.
It’s an interesting read and definitely pertinent to this caching strategy.
Casey
on 21 Feb 12@Justin Reese – I see that they still have valid caches, I just don’t know how you generate their cache key without hitting the DB first. A, B, and C will have timestamp N+1 included in their keys from the latest update, but D and other siblings will have timestamp N from a previous update in their keys.
If you read A (the project) from the DB how do you get to the cache key (timestamp N) for D? Is the project.updated_at value used in the keys of all children? That would essentially re-generate the whole cached tree on a change, but still work off a single DB read. Seems like his solution avoids that though, or at least it isn’t mentioned.
Dmytrii Nagirniak
on 21 Feb 12@DHH and all the guys here,
I wonder how all the caching stuff is being unit/integration/acceptance tested?
I can’t imagine working on the hardest parts of the functionality (caching) without assurance of any kind of tests (and I like fast-ish ones).
Nobody yet mentioned it here (except one guy, briefly).
Cheers, Dmytrii.
Paul Leader
on 21 Feb 12@dhh (and anyone else who might have ideas).
I’ve implemented this caching system for a data visualisation project I’m working on, with a massive improvement is response times from 30+ seconds to sub one second (i.e. actually useful)
However, while it’s fantastically fast in production in dev it is incredibly slow.
The data is presented in date order, so in order to break it up I’ve created a hierarchy of Year, Month, and Day models containing the data, with associated nested partials. This works really well when cached, resulting in almost no DB hits and almost no rendering most of the time. Only the minimum amount of the view has to be regenerated when data changes, and most of the time the top level cache item gets returned.
In development, it now means that rather than grabbing all the data in one query as before, I now do a series of nested small queries. With 3,500 records, that’s rather a lot of queries, and makes it painfully slow.
Any suggestions on how to deal with this kind of performance disparity?
It doesn’t seem to be possible to turn on view fragment caching while you’ve got cache_classes = false, so I can’t do that in development mode.
My short term solution is just to use a subset of the data, but since this is a visaulisation project it would be good to be able to dev with the entire lot.
Anyone got any suggestions?
Jesse
on 21 Feb 12How do you know what the cache key is? You would have to fetch it from the database to know the mtime right? If you’re pulling the record from the database already, I would expect that to be the greatest hit, no?
Am I missing something?
Jesse
on 21 Feb 12Please remove my brain-dead comment. I just realized why this doesn’t matter: the caching is cascaded, so yes a full depth regeneration incurs a DB hit. The next cache hit will incur one DB query for the top-level object—all the descendant objects are not queried because the cache for the parent object includes cached versions for the children (thus, no query necessary).
Kyle
on 22 Feb 12@DHH, this sounds absolutely fantastic. But how does the caching work across multiple app servers? (I’m assuming that you have BCX code running on more than one server)
Thanks.
Paul Leader
on 22 Feb 12@Jesse Bingo. That’s why is works soooo well. If you do it right it doesn’t just eliminate the need to generate the HTML but any need to hit the db. With this caching system in place, our data-vis app is almost instantaneous, it’s actually useable and the code is much nicer.
This discussion is closed.