My dad is a firefighter and fire captain in Niagara Falls, NY. When I told him I had on-call duty for my new job, he was beyond excited. After relaying stories of waking in the middle of the night to head into the hall and getting overtime from his buddies that didn’t want to wake up for work were sick, I had to explain that it’s a different type of action for me. I face issues of a less life-threatening variety, but there’s still plenty of virtual fires to extinguish. Here’s a primer for what being an on-call programmer means at 37signals.
The routine
On-call programmers are rotated around every 2 weeks, and all 8 programmers currently get their fair share of customer support and interaction. Usually we have 2 to 3 programmers on-call on a given week. Support issues from email and Twitter are routed through Assistly, and handled by our awesome support team.
If there’s an issue they can’t figure out, we get a ping in our On Call room in Campfire to check out a certain issue:

These issues range in severity, and they might look like:
- Got an “Oops” page (our standard 500 Server Error page)
- Can’t log in
- Page is messed up or broken
- Incoming email didn’t process or show up
The next step is to FIX IT! If possible, get the customer’s problem figured out in the short term, and hopefully push out a bug fix to stomp it out permanently. Luckily, we’ve got a few tools to help us out debugging. We use a GitHub wiki to share code snippets that make some common issues go faster:
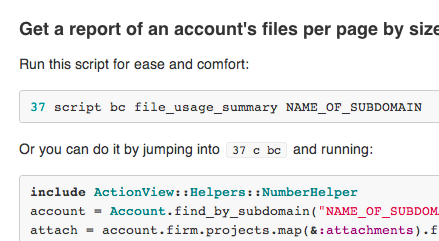
This screenshot shows off a newer piece of our weapon rack as on-call programmers: 37. 37 is our internal tool for doing pretty much anything with our production servers and data. Some of what it covers:
- SSH into any box on our cluster
- Watch a live feed of exceptions streaming in
- Fire up a Rails or MySQL console for any application
- Grep or tail logs over multiple days from a specific account
37 has helped immensely by just the virtue of being a shared tool that we can use Ruby (and Bash!) to automate our daily work. It started as a small set of scripts tossed around on various machines, but it really became a vital part of our workflow once we made it into a repo and documented each command and script.
Once the issue has been debugged/solved/deployed, we’ll log the issue as fixed on Assistly. The support crew handles telling the customer it’s fixed, but sometimes I’ll jump in if it’s a developer/API related issue.
Other channels
There’s a few other channels we pay attention to throughout the day as well. In Campfire we get alerts from Nagios about things that might be going wrong.
Here’s one such example: a contact export from Highrise that was stuck in the queue for too long.
Another incoming channel is the API support google group. Although this is more of a support forum for existing API consumers, we’ll try to jump in and help debug issues if there’s time left over from handling direct customer issues.
Fire!
Our on-call emergencies come in many different flavors. An all-out, 5 alarm fire is rare, but does happen. Typically it’s a slow burning fire: something is smoldering, and we need to put it out before it gets worse.
We’ll learn of these problems in a few ways:
- Nagios alert in Campfire about downtime/inaccessibility
- Twitter eruption
- Support ticket flood
Once we have a handle that it’s not a false alarm, we’ll update the status site and notify customers via @37signals. The number one priority from there is putting out the fire, and it usually involves discussing our attack plan and deploying the fix.
If the fire is really getting out of control and tickets are piling up, sometimes we’ll help answer them to let them know we’re on it. The status site also knows everyone’s phone numbers, so if it’s off-hours we can text and/or call in backup to help solve the problem.

Here’s a few tips I’ve learned from our fires so far:
Be honest
Given I’m relatively new to our apps and their infrastructure, I don’t know my way around 100% yet. Being honest about what you do and don’t know given the information at hand is extremely important. Be vocal about what you’re attempting, any commands you might be running, and what your thought process is. Jumping on Skype or voice iChat with others attempting to debug the problem might also be useful, but if someone is actively trying to hunt down the problem, be aware that might break their flow.
Cool your head
Each problem we get is different, and it’s most likely pretty hairy to solve. Becoming frustrated at it isn’t going to help! Stepping away might not be the best way to de-stress if the fire is burning, but staying calm and focused on the problem goes a long way. Frustration is immediately visible in communication, even via Campfire, and venting isn’t going to solve the problem any faster.
Write up what happened
Post-mortems are an awesome way to understand into how the fires were put out, and what we can do better the next time one happens. Our writeups get pretty in-depth, and knowing the approach used can definitely help out the next time. Especially since we’re remote and spread across many different timezones, reviewing a full report and reflection on the problem is extremely helpful, no matter how small the fire was.
There is no undo!
Issues that crop up repeatedly always have a larger fix in mind. Losing work due to browser crashes and closed windows was a large support issue, until autosave came to the rescue. When not putting out fires, on-call programmers are working on “slack” issues like these, or fixing other long-standing bugs.
Experimentation with how on-call works is definitely encouraged to help our customers faster, and I’m sure our process will continue to evolve. It’s not perfect (what process is?), but I can definitely say it’s been improving. Putting out our virtual fires is still a lot of fun despite all of the stress!
bpo
on 16 Apr 12Which version of Campfire is that?
Nick
on 16 Apr 12@bpo, it’s Flint: http://giantcomet.com/flint
Alice Young
on 16 Apr 12The fact that you need an on-call second level support at all (and that’s what you are, not an on-call programmer) shows that something is not very well tested with your software. One of my systems is about 250K lines of Java+JRuby code, is used by about 80K users daily and can literally run 24/7 for months without needing a restart. In fact, it’s only restarted on upgrades anymore. And if there’s a problem in a thread, the thread is killed, its trace packed up and shipped by email where it can be examined some days later. Granted, native ruby is not nearly as robust and testable as Java code, but you still shouldn’t need a support rotation, or any rotation, for the relatively simple programs you’re running. Learn how to write tests and avoid the pain.
T.J. Barber
on 16 Apr 12Oh dear Alice… What I’m about to say is not sarcasm AT ALL. You’re an excellent programmer, and I tip my hat off to you just because you can tolerate Java enough to get it running on your server. But golly dear, this is 37signals and they know what they’re doing. They write tests. Heck, I believe there was someone who just posted an article about that a couple days ago. I think the purpose of this article is to show people what 37signals does when their servers do go down and how people should react. I don’t think this is a confession at all.
Matt
on 16 Apr 12Did you read the note below the form, Alice? Vapid comments are discouraged.
DHH
on 16 Apr 12Shit, Alice, you got us. Why didn’t I think of this before. If we just switch to Java, then we can use threads, and the thread fairy will make all our problems go away. Thaaaaaaaaaaaanks!
Lonny Eachus
on 16 Apr 12Recent research has revealed that trolls display a curious cognitive disconnect:
They never seem to be aware that what appears to them to be a clear, unobstructed view of the world is really just the underside of the bridge.
Arik Jones
on 16 Apr 12SvN is a like a beacon light for trolls of all kinds. Their responses never get old.
Rupert K Park
on 16 Apr 12It’s easier to write-off Alice as a troll than it is to accept that she might have a perfectly valid point.
I was thinking the exact same thing as I read the article—how could an organization possibly have so many regressions and failures as to require full time 24/7 on-call programmers?
I was glad to see someone else had already commented as such, and then dismayed to see the valid point derided as “trolling” without any logical refutation of her position.
To those of you who can’t read criticism like this with a cognitive eye—you’ll have the software (and costs) that you deserve.
GeeIWonder
on 16 Apr 12Which means not much at all. There was someone who wrote an article about government oversight of ‘the [US] market’ and some new legislation the other day that presented at best a slewed and incomplete understanding of both basic facts and broader implications/context.
Can’t imagine this sort of sarcasm flies in-house, but I could be wrong. It certainly doesn’t make you seem confident in your ‘response’.
Agree with Rupert that it makes it sound like Alice hit a nerve I would guess the sarcasm indicates this was early on in her comment, rather than in the ruby vs. java point, which you could presumably easily falsify (so one wonders why you didn’t)
Smudge
on 16 Apr 12I have a programmer friend who is on-call once every couple months or so. The system he supports is (in short) a mess, and usually these on-call weeks make his life a living hell. But his team is running a live service, so it’s not like they can just file bugs and fix the code for the next release.
BUT, his live would be made much easier if there weren’t so many systemic issues with the entire stack he supports, and while his managers see the on-call rotation as essential to keep the machine greased, he sees his job as a band-aid that masks several bigger organizational issues.
So, despite all of the calls of “troll,” I’m inclined to sort of agree with Alice. Sure, it’s a live service, so live support is always necessary, but when putting out so many fires it’s important to ask where all of the fires are coming from and what can be done to fix it in the long term. (Would love to see an article addressing that!)
Henry T
on 16 Apr 12@37signals
This “on call developer” program is more widely known as “production support” amongst large enterprise organizations.
Welcome to the dark side.
DHH
on 16 Apr 12GeeIWonder, Alice’s response was nonsensical. She talks about how she doesn’t need restart her leviathan of an application for months, which means that she equates bugs or fires with a process outright crashing. We spend little time investigating crash bugs.
We spend time trying to figure out why emails weren’t delivered (often because they get caught in the client’s spam filter or their inbox is over capacity), or why an import of contacts from Excel is broken (because some formatting isn’t right), or any of the myriad of other issues that arises from having variable input and output from an application that’s been used by millions of people.
Saying “fix the bugs” or “add more testing” is so shallow an attempt at “advice” that it constitutes trolling. Like, we were going to read this and think, doh, that’s it, add more testing! Or riiiight, why didn’t we just fix the bugs? That’s it!
Jonathan Lancar
on 16 Apr 12Given her response, I think Alice assumed the problem HAD to be code-related; which the article did not necessarily point-out.
In a small team, a “programmer” is often a SysAdmin, a Support Engineer, and/or a DBA.
Problems can occur at any point in the stack, including appliances and services that can live outside your internal stack (S3 anyone?).
So, in a sense, Alice’s answer could be considered trolling (while she does make an important point) if unlike her, you do consider the entire scope of a running SaaS nowadays.
Daniel
on 16 Apr 12Why would any organization want to be without? Seems like a great thing to have! Imagine if your car’s original designers, engineers and assembly line workers all came to your aid if the air conditioning malfunctioned. Pretty sure stuff would get fixed.
I’d say it’s a question of labels. Alice the Troll actually touched on this, by calling Nick a “second level programmer”. So apparently if you’re a programmer doing support, you’re somehow not really a programmer. You’re “just support”. Which is bullshit of course.
However, many companies do have programmers in their support staff – they just don’t count as programmers. Of course, programmers hired specifically for support aren’t always as skilled as the hot shots that build the apps, but even when they are, they certainly don’t have the same knowledge of the code as the people who wrote it.
Either that, or there’s a tremendous amount of support-specific tools that’ve been built to let the non-programmer support staff into the systems while keeping them from breaking stuff. And if they can’t fix it with those tools, it doesn’t get fixed. And god forbid the support tools have a bug…
I think 37s is doing a great thing by having the actual hot shot programmers who build the apps also handle support. Usually companies only dogfood their own products in terms of use, not support. And you avoid building walls between your employees.
But more than any of the above: Speed. Support requests are simply handled faster and better by having the right people doing support: Those who can fix things.
Henry T
on 16 Apr 12Also, I’m glad to see 37signals post from last week about their minimal approach to testing is keeping the new hires busy and up late at night tracking down bugs.
http://37signals.com/svn/posts/3159-testing-like-the-tsa
Thanks guys for the self-imposed American job stimulus you’re providing our country.
Rupert K Park
on 16 Apr 12Wouldn’t it be better (and cheaper) if the air conditioning simply didn’t malfunction?
That’s why an organization would want to have no need for this kind of emergency support.
I’ve put engineers on 24/7 support in the past. It was a unique situation in which their code base was so tremendously bad that the organization benefited from preventing them from externalizing the cost of their bad design, and encouraged that segment of the engineering organization to clean up shop.
It’s not something you want to aspire to.
Craig
on 16 Apr 12The kind issues you describe, lost emails or importing of contacts failing, don’t seem like they should require developer support to fix. They are standard support issues that good back end systems and support personnel can fix fairly easily.
DHH
on 16 Apr 12Nobody is on 24/7 support except in the sense that if the application is having serious, system-wide issues. I can assure you that every single company running a SaaS application with paying customers have programmers that are available 24/7 if the shit hits the fan. If they do not, they’re going to be out of business in short order.
If your system goes down Friday at 11:30pm, and you need programmers to help fix that issue, you’re dead in the water if you wait until next Monday at 9pm.
So being on-call generally means that you help customers with harder problems during our regular hours and deal with root-cause investigations when there’s nothing in the queue.
The only people who develop software as a service for millions of people that never has bugs, never confuses users, and never requires operational assistance are either delusional or pay the 10-100x development cost to operate at that level of criticality (warranted by consequences such as death or loss of millions).
Anonymous Coward
on 16 Apr 12I can’t even imagine how busy the On-Call-Developers are these days since 37signals just threw out their old BaseCamp product and rewrote from scratch.
For the 8 years in which that product existed, I assume there were thousands of bugs fixes over that time.
Now, time to start over and fix all those same bugs over again :(
GeeIWonder
on 16 Apr 12Pretty interesting discussion, and pretty convincing answer IMO by DHH (a couple of times) above. Also, Alice didn’t do herself any favours with what coul;d certainly be construed as a snarky tone and a couple of cheap shots.
Also Kudos to Nick on the OP for outlining the process stream and tools used so well.
Arik Jones
on 16 Apr 12And you’d be out of a job. Software that would never malfunction is about as possible as the sun never rising.
Even worse is your argument doesn’t make sense. What you’re saying is that the act of maintaining software is a sign of programmer incompetence? That’s ridiculous.
If you don’t mind, please show me some software that doesn’t fail or have bugs, ever?
Eric Hayes
on 16 Apr 12Obviously 37 Signals doesn’t live in The Real World™ ;/)
Just kidding, I love these behind-the-scenes posts, please keep them coming!
Alice Does Not Exist
on 16 Apr 12Nice try stirring up some controversy. I think that belongs over on Techcrunch.
Elliot
on 17 Apr 12@Craig – They’ve mentioned in the past that everyone gets rotating duties, the support personnel are the programmers. Why wouldn’t you want the people with the most domain knowledge to be out there ready to fix unforseen issues.
Jace
on 17 Apr 12@Alice, @Henry, @AC
+100
T.J. Barber
on 17 Apr 12DHH, you’re one awesome bro. Love how you can shut up the trolls with a word.
Eric Hayes, I totally agree with you. I loved the post where they showed off their desks. I’d love more of that kind of stuff. ;)
Albert Francis
on 17 Apr 12I’m sorry, but I also have to agree with Alice here.
Requiring on-call programmers is a sign of a broken system. I have been developing software for both small companies and large enterprise systems for a long time and the only times we needed on-call were when we were deploying or expecting HUGE amounts of load (holidays etc.).
That said, as developers we are all ultimately on call all the time as long as we are employed by a company, but in my career having been called to fix an issue is extremely rare (less that once a year).
Maybe this post reveals a major drawback with continous deployments? Releasing on a regular schedule definitely has benefits, for instance by having a concentrated QA pass as well as scheduling with major feature releases etc. It also avoids having on-call like you seem to do, since no one can just push random code out at any time.
If you don’t have resources for dedicated system adminstrators or support staff, that’s fine. But taking up precious development time to fix issues that really should have been caught before it reached production is short sighted in my opinion.
m
on 17 Apr 12We formalized the support role just a few months ago on my team, and it stands out as good decision.
Having a rotating support role not only allows the rest to focus, but it also does wonders to motivate everyone to invest in keeping up code/infrastructure quality. It also gently forces people to understand components that previously “aren’t my job”.
Levi Figueira
on 17 Apr 12Who let the trolls out…? #songinyourhead
I just find it hilarious how these fanboys come in here, guns ablaze, trying to poke holes to make a “religious” statement and yet don’t realize the ridicule they put themselves through…
I’ve worked in a major computer/networking security consulting company. For a period of time, I was on call. We trusted our systems and implementations yet we had an SLA, and that SLA required 24/7 availability of direct, low-level, support. In the 6 months I had a company phone with me at all times, I don’t remember a single call past 9pm on weekdays and at any time during weekends. That fact does invalidate the point that we had a first-level support team that handled the basic stuff. The reality is we were paid to had that second-level personnel available SHOULD ANYTHING happen.
You can’t create support levels for things that you know will break. That’s not support: that’s bad implementation. This article is talking about the support: things you can’t predict no matter how well you test your code or stable your application is, technically.
These comments remind me of Mac vs Windows comments on gaming forums, where Windows fanboys simply assume a Mac user has little to no knowledge about computers/hardware, is naive, got ripped off and is clueless about it all… Little do they know that, quite frequently, a Mac user may know more about Windows and hardware then they do, which was exactly why they decided to invest in a Mac…
sigh
James
on 17 Apr 12Requiring on call programmers isn’t necessarily a sign of a broken system, it is a sign of committed customer service.
If you are willing to let your customers wait for 12-18 hours for a support call to be dealt with, you either have very understanding customers or you have very frustrated customers.
Nik
on 17 Apr 12Suggestion: hire some sysadmin’s and keep programmers programming.
Rob
on 17 Apr 12A good article, and the “Alice” comment obviously stoked a few fires.
I agree with the article. You do need some form of support. As a business you usually can’t afford any downtime. We’re all human so errors or oversights will creep into our code (and frameworks!). Also there is no environment like a live system. You can try to imitate it, but it’s just not the same. So it can be hard to plan for every possible outcome.
The important thing is that you have some form of support when something goes wrong and get the issue fixed. You then look into what caused it to try and stop it happening again.
Most of the time, I’m willing to bet it’s not related to the code written, but rather cpu/memory/network/db load issues etc… or unexpected/missed circumstances. The dev team is merely there to help hunt down the issue with any of the systems guys.
Essuu
on 17 Apr 12As ever, folk are jumping to conclusions without sufficient data.
Having on-call staff is really mandatory if you’re running a 24×7 operation. The important question is – how often are they called ?
This blog post implies that it’s quite often or at least often enough to write a blog post about how they do it but we don’t know that. Maybe Nick decided to post about it to reassure people that they have a plan in place to deal with emergencies. If that’s the case, thanks, I appreciate that 37s is thinking about these things and planning for all eventualities.
If on-call is being called out more than once a week though, I’d say there’s a systemic issue that needs sorting out.
But if on-call gets called less than once a month, that’s probably reasonable for what is, in fact, a very high volume transactional application.
Fadzlan
on 17 Apr 12Oh boy. Now someone is getting lynched because they admit their systems has bugs! Horror, I know.
For those who said their system are much more robust, do you handle things at scale such as 37Signals? Problems that happens one in a million might not occur is small scale setup, but have much likelihood to occur in a system running at a scale.
I for one, think its cool that one of the programmer is handling support (on rotation basis that is). As much as I like developing software, getting in touch with the users reminds me what I write the software for.
Richard
on 17 Apr 12I did not read much beyond DHH’s 3rd response, but quite frankly I have lost a lot of respect for 37signals today. I am not a programmer and don’t give a crap whether or not Alice is completely off her rocker. Why the heck would you respond to someone that way? (publicly or otherwise) Every single interaction is a chance to create “raving fans”. Instead someone at 37signals has found it better to engage/belittle someone for all their customers and potential customers to see
Yuan
on 17 Apr 12@DHH
I’m curious to know if you equally participate in the “on call developer” program from your home in the south of Spain.
Kyle
on 18 Apr 12Do you think you could write more about this 37 tool? I would love to hear more about how it works. It sounds interesting and could be something that other companies would love to build for themselves.
JjP
on 18 Apr 12Why would I wanna do that? To hear from sysadmin: “I’m not gonna fix that, it’s not my job”? No, thanks.
This discussion is closed.