Different models in your Rails application will often share a set of cross-cutting concerns. In Basecamp, we have almost forty such concerns with names like Trashable, Searchable, Visible, Movable, Taggable.
These concerns encapsulate both data access and domain logic about a certain slice of responsibility. Here’s a simplified version of the taggable concern:
module Taggable
extend ActiveSupport::Concern
included do
has_many :taggings, as: :taggable, dependent: :destroy
has_many :tags, through: :taggings
end
def tag_names
tags.map(&:name)
end
end
This concern can then be mixed into all the models that are taggable and you’ll have a single place to update the logic and reason about it.
Here’s a similar concern where all we add is a single class method:
# current_account.posts.visible_to(current_user)
module Visible
extend ActiveSupport::Concern
module ClassMethods
def visible_to(person)
where \
"(#{table_name}.bucket_id IN (?) AND
#{table_name}.bucket_type = 'Project') OR
(#{table_name}.bucket_id IN (?) AND
#{table_name}.bucket_type = 'Calendar')",
person.projects.pluck('projects.id'),
calendar_scope.pluck('calendars.id')
end
end
end
Concerns are also a helpful way of extracting a slice of model that doesn’t seem part of its essence (what is and isn’t in the essence of a model is a fuzzy line and a longer discussion) without going full-bore Single Responsibility Principle and running the risk of ballooning your object inventory.
Here’s a Dropboxed concern that we mix into just the Person model, which allows us to later to route incoming emails to be from the right person:
module Dropboxed
extend ActiveSupport::Concern
included do
before_create :generate_dropbox_key
end
def rekey_dropbox
generate_dropbox_key
save!
end
private
def generate_dropbox_key
self.dropbox_key = SignalId::Token.unique(24) do |key|
self.class.find_by_dropbox_key(key)
end
end
end
Now this is certainly not the only way to slice up chubby models. For Visible concern, you could have Viewer.visible(current_account.posts, to: current_user) and encapsulate the query in a stand-alone object. For Dropboxed, you could have a Dropbox stand-alone class.
But I find that concerns are often just the right amount of abstraction and that they often result in a friendlier API. I far prefer current_account.posts.visible_to(current_user) to involving a third query object. And of course things like Taggable that needs to add associations to the target object are hard to do in any other way.
It’s true that this will lead to a proliferation of methods on some objects, but that has never bothered me. I care about how I interact with my code base through the source. That concerns happen to mix it all together into a big model under the hood is irrelevant to the understanding of the domain model.
We’ve been using this notion of extracting concerns from chubby models in all the applications at 37signals for years. It’s resulted in a domain model that’s simple and easy to understand without needless ceremony. Basecamp Classic’s domain model is 8+ years old now and still going strong with the use of concerns.
This approach to breaking up domain logic into concerns is similar in some ways to the DCI notion of Roles. It doesn’t have the run-time mixin acrobatics nor does it have the “thy models shall be completely devoid of logic themselves” prescription, but other than that, it’ll often result in similar logic extracted using similar names.
In Rails 4, we’re going to invite programmers to use concerns with the default app/models/concerns and app/controllers/concerns directories that are automatically part of the load path. Together with the ActiveSupport::Concern wrapper, it’s just enough support to make this light-weight factoring mechanism shine. But you can start using this approach with any Rails app today.
Enjoy!


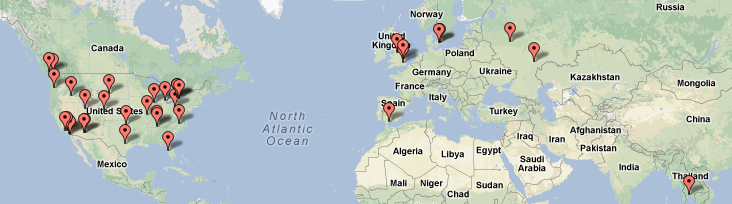 The 36 people of 37signals have lived and worked from the following cities during their time at the company:
The 36 people of 37signals have lived and worked from the following cities during their time at the company: