
What would you say if I told you that you could get more precise, actionable, and useful information about how your Rails application is performing than any third party service or log parsing tool with just a few hours of work?
For years, we’ve used third party tools like New Relic in all of our apps, and while we still use some of those tools today, we found ourselves wanting more – more information about the distribution of timing, more control over what’s being measured, a more intuitive user interface, and more real-time access to data when something’s going wrong.
Fortunately, there are simple, minimally-invasive options that are available virtually for “free” in Rails. If you’ve ever looked through Rails log files, you’ve probably seen lines like:
Feb 7 11:27:49 bc-06 basecamp[16760]: [projects] Person Load (0.5ms) SELECT `people`.* FROM `people` WHERE `people`.`id` = ? LIMIT 1 Feb 7 11:27:49 bc-06 basecamp[16760]: [projects] Rendered events/_post.rhtml (0.4ms) Feb 7 11:27:50 bc-06 basecamp[16760]: [projects] Rendered project/index.erb within layouts/in_global (447.2ms) Feb 7 11:27:50 bc-06 basecamp[16760]: [projects] Completed 200 OK in 529ms (Views: 421.7ms | ActiveRecord: 58.0ms)
You could try to parse these log files, or you could tap into Rails’ internals to extract just the numbers, but both of those are somewhat difficult and open up a lot of areas for things to go wrong. Fortunately, in Rails 3, you can get all this information and more in whatever form you want with just a few lines of code.
All the details you could want to know, after the jump…
Dipping into the well of knowledge
In Rails 3, ActiveSupport::Notifications provide you with direct access to this information. Rails generates instrumentation events that include information about each part of a request/response cycle, including how long it took. Rails 3+ logs are generated by subscribing to these events and writing them to log files in a specified format.
In order to get the performance data we’re interested in, we add a set of listeners that subscribe to these performance events, format them the way we want, and then re-emit them. Our typical usage looks like:
ActiveSupport::Notifications.subscribe /process_action.action_controller/ do |*args|
event = ActiveSupport::Notifications::Event.new(*args)
controller = event.payload[:controller]
action = event.payload[:action]
format = event.payload[:format] || "all"
format = "all" if format == "*/*"
status = event.payload[:status]
key = "#{controller}.#{action}.#{format}.#{ENV["INSTRUMENTATION_HOSTNAME"]}"
ActiveSupport::Notifications.instrument :performance, :action => :timing, :measurement => "#{key}.total_duration", :value => event.duration
ActiveSupport::Notifications.instrument :performance, :action => :timing, :measurement => "#{key}.db_time", :value => event.payload[:db_runtime]
ActiveSupport::Notifications.instrument :performance, :action => :timing, :measurement => "#{key}.view_time", :value => event.payload[:view_runtime]
ActiveSupport::Notifications.instrument :performance, :measurement => "#{key}.status.#{status}"
end
In just a dozen or so lines of code, we’ve subscribed to action_controller instrumentation events, extracted the information that we’re interested in (time spent in database queries, rendering views, total time and status code, segmented by controller, action, format, and hostname) and re-emitted that information as “performance” events. We do something similar for action_mailer, active_record, etc., in each case emitting similarly formatted performance events.
Sidenote: what about Rails 2.3.x?
Rails got ActiveSupport::Notification events in version 3.0. For those applications of ours that are still on Rails 2.3.x, we resort to the less elegant approach of around_filter’s and aliasing methods like render, deliver, and log to _with_instrumentation methods which time the original method and pass the results along.
Storing the data
We’re big fans of statsd, which is a data-over-UDP approach to handling timeseries data (we use our own Redis-backed implementation which is ‘wireline’ compatible with Etsy’s original implementation). Statsd lets us send as much information as we want without having a substantial impact on app performance, and without requiring that the receiver be up for the apps to remain available. Since we send data via UDP, we can take down the statsd server for maintenance and only incur data loss, with no impact on the applications themselves.
Statsd stores several aggregates of data, so we’ve configured our setup to store near real-time data for the last hour, per-minute aggregates for the last week, and per-10-minute data indefinitely.
To get those performance events that we generated above into statsd, we subscribe to those events (via an initializer after setting up MyApp.statsd with the statsd host and port) and send them along to statsd, doing something like:
def send_event_to_statsd(name, payload)
action = payload[:action] || :increment
measurement = payload[:measurement]
value = payload[:value]
key_name = ::Statsd.clean_name("#{name.to_s.capitalize}.#{measurement}")
MyApp.statsd.__send__ action.to_s, key_name, (value || 1)
end
ActiveSupport::Notifications.subscribe /performance/ do |name, start, finish, id, payload|
send_event_to_statsd(name, payload)
end
This converts the instrumentation events into a key and value to be sent to statsd, either as a “counter”, a “gauge”, or a “timer”.
We also supplement the information from these instrumentation events by feeding HAProxy events, bluepill health checks on our unicorns, and statistics from memcached and redis into statsd via parser scripts.
Using the data
Once we have the data in statsd, we do a few things with it:
- We have Nagios alerts that monitor error rates, total request time, etc. on an aggregate and per-host basis, and alert when they cross certain thresholds that indicate something unusual is going on.
- The most commonly used information gets presented in a standardized dashboard for each application and host, with additional details on mail delivery, database performance, uptime, and background services like Resque. For example, below is what our application overview for the dash application itself looks like:
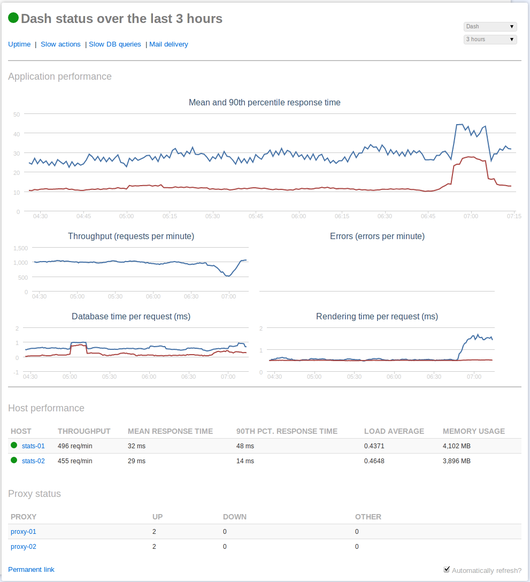
- Every datapoint that gets into statsd, as well as data from third party services, Nagios checks, and our internal financial systems ends up in a tool we call “Flyash”, which does one thing—it graphs timeseries data. Flyash has some support for saving views, but its real strength comes when you’re digging deep into something and want to look at information in a way that’s different from how you might normally look at it, Flyash is our way to do that – for example, if I wanted to compare the number of application exceptions with average daily Smiley score, I could do that:
In all, we have 457,739 different metrics available in Flyash right now.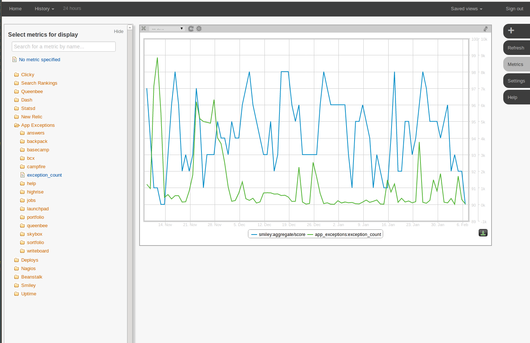
Why would you do this yourself?
To some extent, we’re reinventing the wheel. There are services out there that monitor your applications’ performance, and as long as you don’t try to get too fancy or look too closely at the data, those are fine.
There are a few reasons that we’ve migrated to doing something like this:
- Non-invasive and lightweight. Almost all of our homegrown instrumentation – especially on Rails 3 applications – is fairly non-invasive. In most cases, we listen to existing instrumentation events and parse them rather than redefining existing functions. This lowers the “surface area” for bugs in the instrumentation to cause customer-facing problems, and the fact that we use UDP means we don’t have to worry much about the failure of a remote service impacting application availability.
- No manipulations. Most third party services report mean, and if you’re lucky, some approximate measure of distribution like apdex. This is better than nothing, but still leaves a lot to be desired – mean is often a pretty poor indicator of true performance. With our setup, we store min, max, mean, 90th percentile, and standard deviation for all timing information in a given time period.
- Everything in one place. When you’re using third party services, you end up bouncing from site-to-site to try to understand what’s happening, and it can be hard to get a full picture, especially in a crisis like an outage. Flyash started for us as a way to bring all this data into one place.
So sure, we’re reinventing the wheel a little bit, but I think we’re ending up with a better wheel as a result of it. We have a better understanding of what’s happening with our applications, and as a result, we’ve been able to respond to and fix problems more quickly when they occur.
Have questions about what we’re measuring or what we’re doing with that? Feel free to ask below, and we’ll try to answer as many questions as we can.
Kevin Haggerty
on 14 Feb 12Noah – Thanks for this post. Fantastically detailed. Any possibility of sharing the “Flyash” tool out to the wider world?
David Radcliffe
on 14 Feb 12Great post. Nice to see what you’re really using. Like Kevin, I’d also be interested in using the Flyash tool. Are you using statsd as your final data storage or are you using Graphite/Whisper?
John Bachir
on 14 Feb 12WANT
john Hinnegan
on 14 Feb 12How are you configured to store the percentile?
Any chance of Flyash getting open sourced?
Ivan
on 14 Feb 12I doubt 3rd party providers would be very happy with that happening.
Jeff Putz
on 14 Feb 12I hate it when blogs say “after the jump.” That’s amateur. Either let the whole thing appear in my RSS feed, or don’t bring attention to it.
Philip Hallstrom
on 14 Feb 12Another option is request-log-analyzer
EH
on 14 Feb 12Thanks for this, it’s fun stuff for former sysadmins. :)
Jesper
on 14 Feb 12This is seriously impressive. Are there plans to release any of it?
(In addition, I agree with what Jeff said in wanting a full text feed, although I don’t agree with the way he said it.)
NL
on 14 Feb 12No specific open source plans for Flyash at the moment, but it’s something I’ve thought a little about.
@David – no use of Graphite/Whisper for us. We intentionally didn’t want to add a bunch of dependencies, particularly those that we aren’t as familiar with. Our implementation parks the first level of aggregation (the near real-time data) in Redis, and later aggregations live essentially in flat files on disk (which as crazy as it sounds, is actually suitably fast for our needs).
Daniel Von Fange
on 14 Feb 12Jesper, that does look beautiful.
+1 for open sourcing any of it. Would love to play with your redis backed statsd.
Daniel Von Fange
on 14 Feb 12Whoops, s/Jesper/Noah/g in previous post.
Pete
on 14 Feb 12Flyash looks like a pretty serious implementation of a BI tool. +1 to the list of people asking for source or at least details on how you build the cubes.
Stefan
on 14 Feb 12Very interesting! I once worked as a contract worker for a very large IT company here in Germany. We were working on a Software that contained components written in different languages (C++, C#.NET, ...) I wrote a lib (and ported it to some languages ;-) that sent trace-messages via UDP. That way we could trace the application seamless(!) through all the components, no matter what language used. And as you said: With no impact on the application. If one of our 3000 users had a problem, with UDPTrace we always found out why. Just for fun I once traced my PHP WebApp, hosted on a virtual server, sending the data at home, receiving it all in a private network using port forwarding. Very awesome :-) I think I will dig deeper into this one. Thank you very much for your post!
Brian Reath
on 14 Feb 12+1 to seeing how your backend timeseries data store is implemented.
Mat
on 14 Feb 12Noah, thanks for writing this up.
How excatly do you track gauges with StatsD?
NL
on 14 Feb 12@Mat – good question.
Gauges aren’t part of Etsy’s “reference” implementation as far as I know (last I checked, there’s a pull request for it outstanding).
Our implementation accepts a metric with a ”|g” data type (as opposed to ”|c” and ”|ms” for counters and timers, respectively), and currently, it stores those values as is, unaltered, indefinitely—we never aggregate or average them. This means we use them pretty sparingly, since they can grow to be quite large, but they’re a good fit for certain use cases where the data is relatively sparse but you always want to preserve each measurement.
Marcel
on 15 Feb 12I would also be very interested in seeing (some of the) source or implementation details of Flyash. We’re looking for something similar at the moment, but Graphite doesn’t really fit into our architecture and looks way more complex than your tool.
Mat
on 15 Feb 12@Noah – thanks, that’s what I was expecting :)
We are using StatsD/Graphite as well and find it a great tool in addition to NewRelic, log tailing, etc. But setting up Graphite was quite a bit of work. I certainly wouldn’t mind if you open sourced an integrated solution…
In the meantime I’d recommend (as existing alternatives) https://github.com/Shopify/statsd-instrument/ for pushing data into StatsD and e.g. https://github.com/mat/graphite-lil-more-beautiful for displaying it.
Gerhard
on 15 Feb 12At GoSquared, we use Graphite extensively and have open-sourced the chef graphite-cookbook for getting it all up and running. There is an initial time investment, yes, but once it was done, I never had to touch it. Also, graphiti looked as a good alternative to graphite-web, I’m still to try it out.
Edgar
on 16 Feb 12two words….huuu fancy…
Tom
on 16 Feb 12Thanks for sharing. I ll cehck out Statsd for sure now :)
Douglas F Shearer
on 16 Feb 12It looks like the charts on the dash and in Flash are generated using different tools. What chart libraries are you using to render them? How do you display any regions of missing data?
Andrew
on 16 Feb 12How did you choose the intervals for storing the data (1 hour real-time, 1 week minutely, etc)? Is it a function of disk space and query time, or does the value of the data decrease that quickly?
NL
on 16 Feb 12@Douglas—they’re both generated with Highcharts but with somewhat different options applied. We also use Protovis in a couple places in the dash.
Kevin Ball
on 17 Feb 12Great, thanks for sharing this! I love the non-blocking approach to logging data. Do you do any sort of analyzing/splitting data by things like user id, location, etc? If so, what sorts of tooling do you use for that?
Farsi dictionary
on 21 Feb 12Thanks for sharing, it’s really useful.
This discussion is closed.