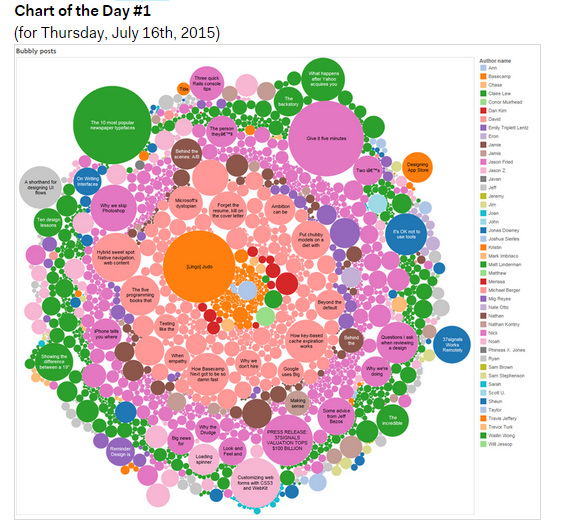
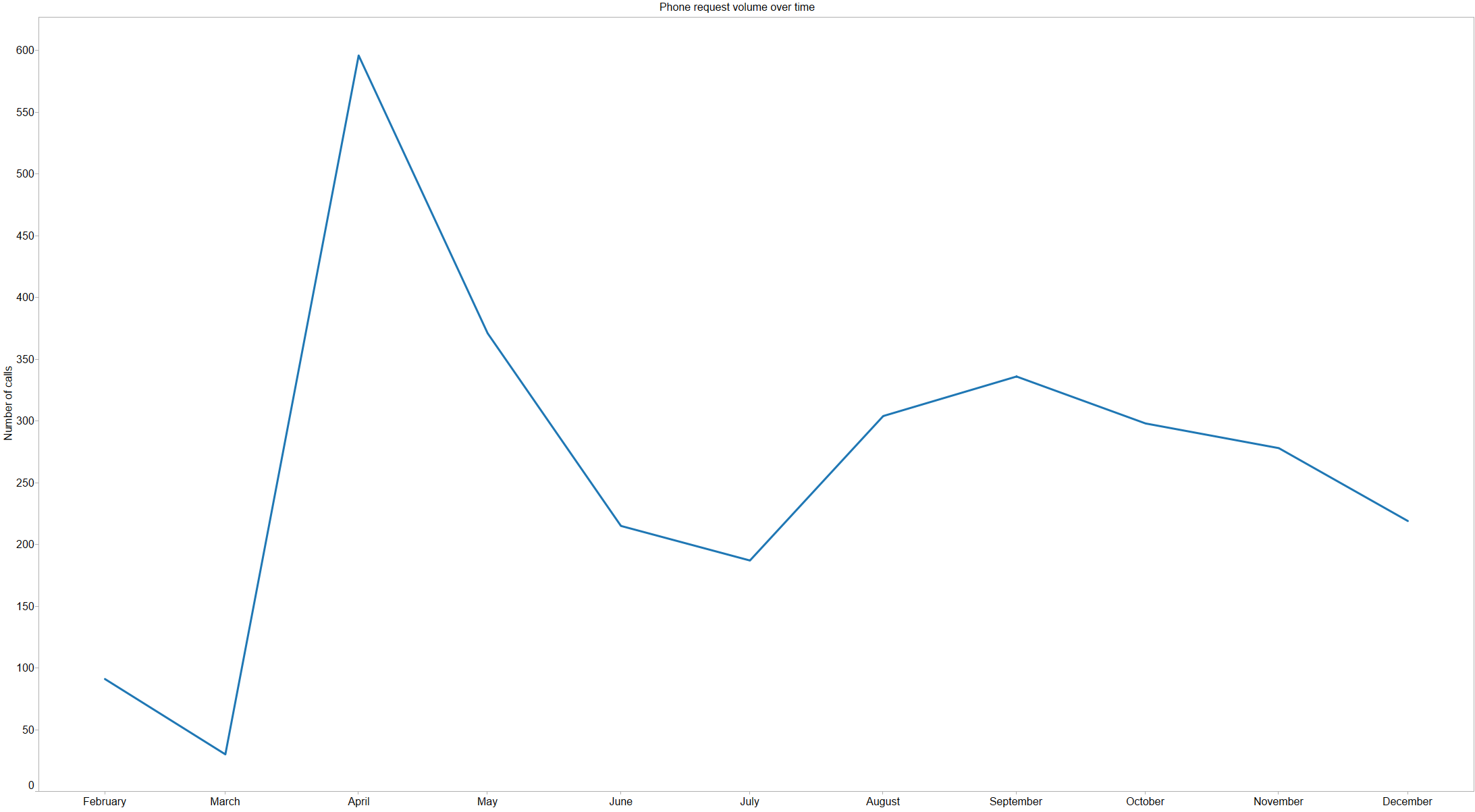
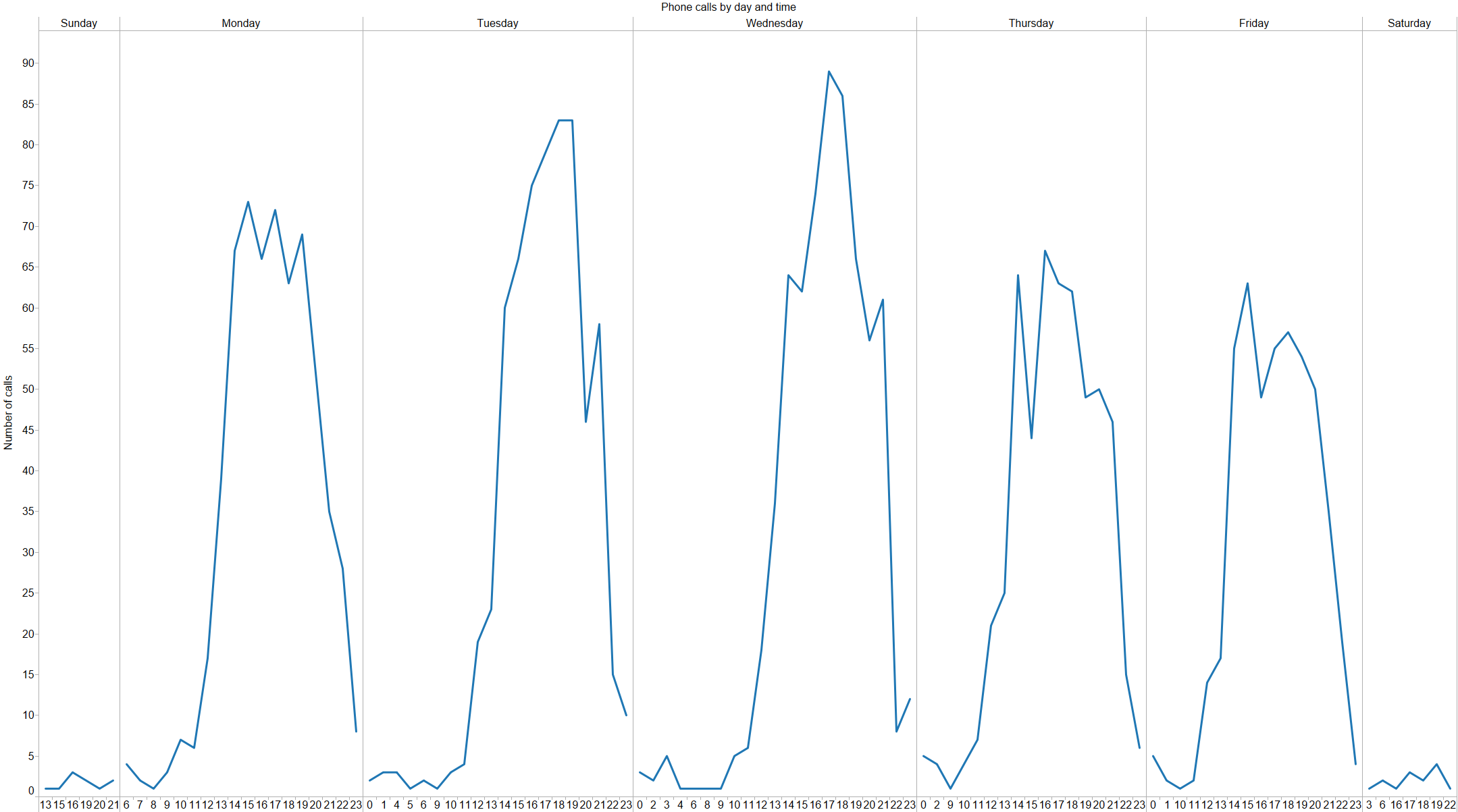
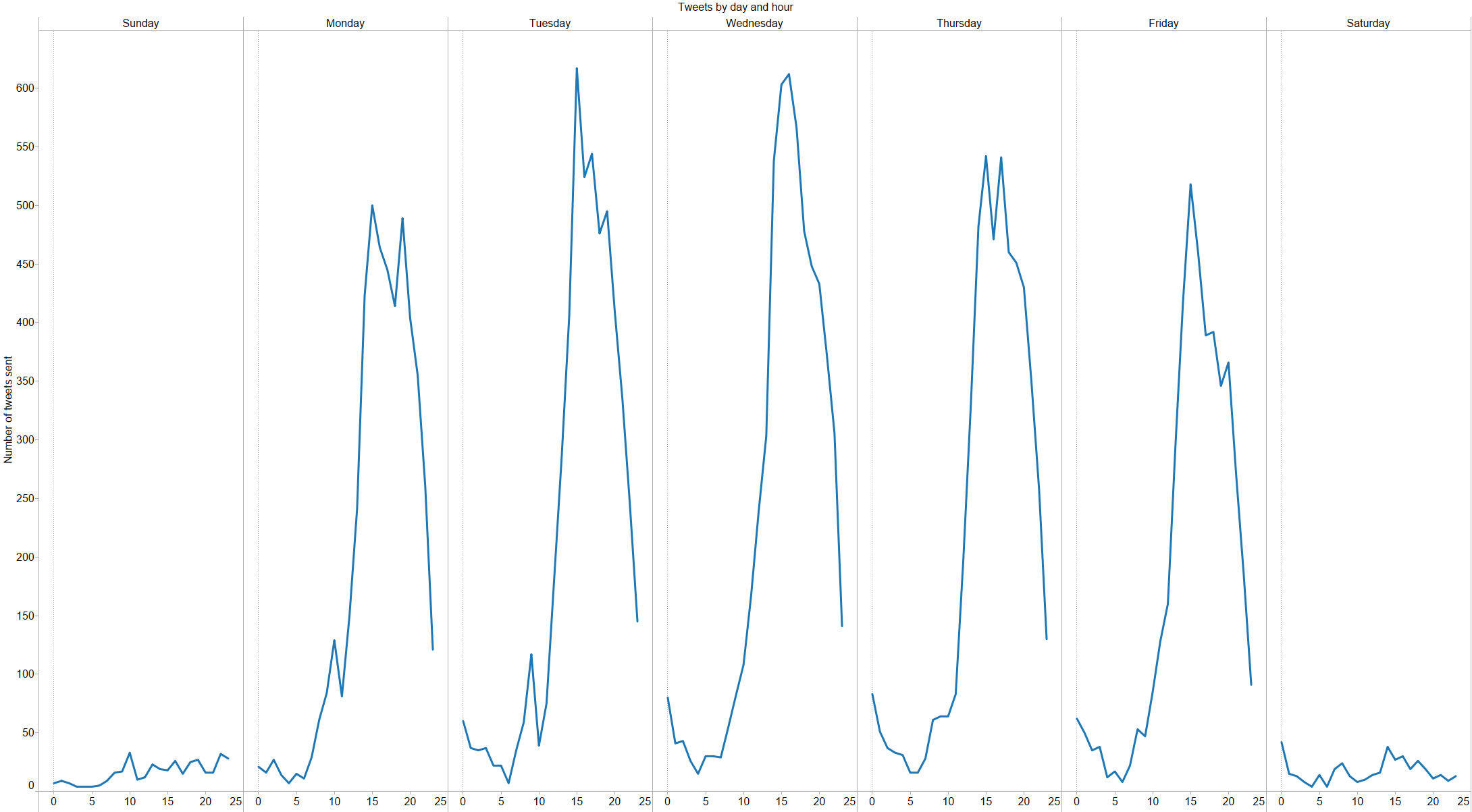
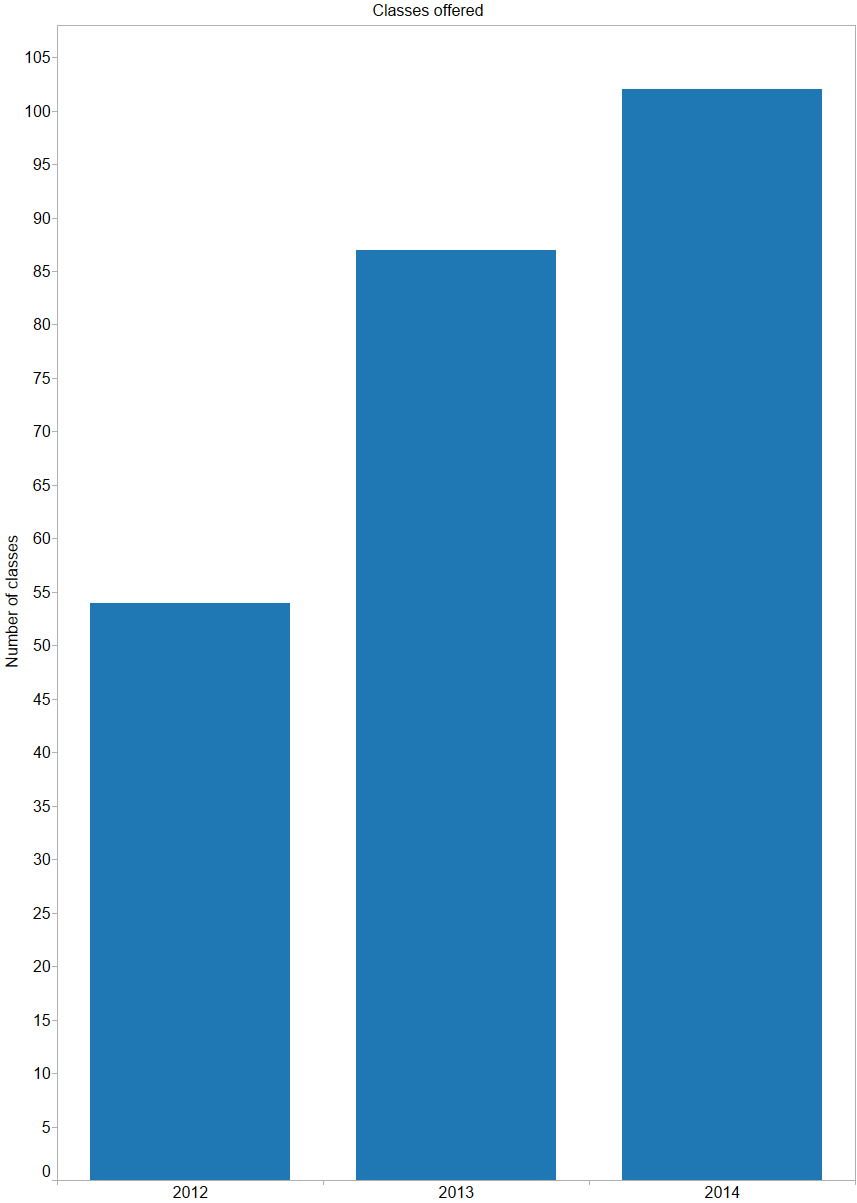
We’ve talked a lot about the Apple Watch internally, and even thought a bit about how Basecamp might work on it. A number of Basecampers have gotten Apple Watches, and reviews have been mixed; some people returned their watch, others wear it every single day. Our unscientific, non-representative sentiment runs probably 50/50 satisfied/dissatisfied with the watch.
A study reporting high levels of customer satisfaction with the Apple Watch made the round of news sites last week, from the New York Times to Fortune to re/code. The same study was also mentioned by Tim Cook on the most recent Apple earnings call. The study was conducted by Creative Strategies, Inc for Wristly, and you can read the whole report on their website.
I’ve never touched an Apple Watch, and I personally don’t spend a lot of time thinking about it. Even so, when I see a study like this, especially one that receives so much press attention and that runs contradictory to other data points (such as the reactions from my colleagues), my attention turns to understanding more about the details of how they conducted the study and drew their conclusions. Examining this study in more detail, I find four major reasons to be skeptical of the results that received such media interest.
Are these apples and oranges?
One of the most talked about conclusions from this study was that the Apple Watch had a higher satisfaction level than the iPhone and iPad had following their introduction in the market. This conclusion is drawn by comparing the “top two box” score from Wristly’s survey (the portion of consumers reporting they were “very satisfied/delighted” or “somewhat satisfied” with their watch) against satisfaction scores from surveys conducted by ChangeWave Research in 2007 and 2010.
Without going into the quality of those original surveys, there are two clear differences between the Apple Watch research and the iPad and iPhone surveys that make this sort of comparison specious:
- Different panels: in order for this sort of comparison to be useful, you’d need to ensure that the panels of consumers in each case of roughly equivalent – similar demographics, tech familiarity, etc. There isn’t really sufficient information available to conclude how different the panels are, but the chances that three very small panels of consumers gathered over an eight year span are at all similar is exceedingly low. A longitudinal survey of consumers that regularly looked at adoption and satisfaction with new devices would be fascinating, and you could draw some comparisons about relative satisfaction from that, but that isn’t what was published here.
- Different questions: the Apple Watch survey asked a fundamentally different question than the earlier work. In Wristly’s survey, they appear to have measured satisfaction using a five point Likert-type scale: they had two positive and two negative rankings surrounding a fifth neutral ranking. By way of contrast, the ChangeWave research for both the iPhone and iPad used a four-point Likert scale (two positive and two negative ratings with no neutral ground) with a fifth “don’t know” option. The question of whether a four or five point scale is a better choice isn’t necessarily settled in the literature, but it’s obvious that the top-two-box results from the two aren’t directly comparable.
Who are you asking?
The conclusions of a survey are only as good as the data you’re able to gather, and the fundamental input to the process is the panel of consumers who you are surveying. You want a panel that’s representative of the population you’re trying to draw conclusions from; if you’re trying to understand behavior among people in California, it does you no good to survey those in New York.
There are a lot of techniques to gather survey panel members, and there are many companies dedicated to doing just that. You can offer incentives for answering a specific survey, enter people into a contest to win something, or just try talking to people as they enter the grocery store. Panel recruitment is hard and expensive, and most surveys end up screening out a large portion of generic survey panels in order to find those that are actually in their target population, but if you want good results, this is the work that’s required.
Wristly’s panel is an entirely opt-in affair that focuses only on Apple Watch research. The only compensation or incentive to panel members is that those who participate in the panel will be the first to receive results from the research.
It’s not hard to imagine that this sort of panel composition will be heavily biased towards those that are enthusiastic about the watch. If you bought an Apple Watch and hated it, would you choose to opt-in to answer questions about it on a weekly basis? I wouldn’t. (Credit to Mashable for noting this self-selection effect).
To Wristly’s credit, they do attempt to normalize for the background of their panel members by splitting out ‘Tech insiders’ from ‘Non-tech users’ from ‘App builders’ from ‘Media/investors’, which is a good start at trying to control for a panel that might skew differently from the general population. Even this breakdown of the data misses the fundamental problem with an opt-in panel like this: the massive self-selection of Apple Watch enthusiasts.
What’s the alternative? Survey a large number of consumers (likely tens of thousands) from a representative, recruited panel; then, screen for only those who have or had an Apple Watch, and ask those folks your satisfaction questions. This is expensive and still imperfect — recruited research panels aren’t a perfect representation of the underlying population — but it’s a lot closer to reality than a completely self-selected panel.
Where are the statistics?
The survey report from Wristly uses language like “We are able to state, with a high degree of confidence, that the Apple Watch is doing extremely well on the key metric of customer satisfaction” and
“But when we look specifically at the “Very Satisfied” category, the differences are staggering – 73% of ‘Non Tech Users’ are delighted vs 63% for ‘Tech Insiders’, and only 43% for the ‘App Builders’”.
Phrases like “high degree of confidence” and “differences are staggering” are provocative, but it’s hard to assess the veracity of those assessments without any information about whether the data presented has any statistical significance. As we enter another presidential election season in the United States, political polls are everywhere and all report some “margin of error”, but no such information is provided here.
The fundamental question that any survey should be evaluated against is: given the panel size and methodology, how confident are you really that if you repeated the study again you’d get similar results? Their results might be completely repeatable, but as a reader of the study, I have no information to come to that conclusion.
What are the incentives of those involved?
You always have to consider the source of any poll or survey, whether it’s in market research or politics. A poll conducted by an organization with an agenda to push is generally less reliable than one that doesn’t have a horse in the race. In politics, many pollsters aren’t considered reliable; their job isn’t to find true results, it’s to push a narrative for the media or supporters.
I have no reason to believe that Wristly or Creative Strategies aren’t playing the data straight here—I don’t know anyone at either company, nor had I heard of either company before I saw this report. I give them the benefit of the doubt that they’re seeking accurate results, but I think it’s fair to have a dose of skepticism nonetheless. Wristly calls itself the “largest independent Apple Watch research platform” and describes its vision as “contribut[ing] to the Apple Watch success by delivering innovative tools and services to developers and marketers of the platform”. It’s certainly in their own self-interest for the Apple Watch to be viewed as a success.
So what if it’s not great research?
There’s a ton of bad research out there, so what makes this one different? For the most part, nothing — I happened to see this one, so I took a closer look. The authors of this study were very good at getting media attention, which is a credit to them — everyone conducting research should try hard to get it out there. That said, it’s disappointing to see that the media continues to unquestioningly report results like this. Essentially none of the media outlets that I saw reporting on these results expressed even the slightest trace of skepticism that the results might not be all they appear on first glance.