I’m going to give away all of my secret sauce, and tell you the three things that are required to be successful at business analytics (or data science, or whatever you want to call it):
1) Know at least a little bit about what you’re talking about.
At its foundation, business analytics is about converting a rather broad question (like “why do people cancel?”) into a set of specific questions that you can answer with data. This takes a bit of knowledge of what you’re talking about—you need the ability to construct hypotheses (e.g., people might cancel because they left the company, or because their corporate IT department rejected it, or…), and you need to know where you can get the answers. The best statistician in the world will be useless if they don’t get the context of the business.
A theoretician might call this “domain knowledge”, but all this is is the ability to know what you’re looking for and where to find it. There are no real shortcuts here – it takes exposure to your content matter to pick this up. Just open up the firehose—read as much as you can about your business and industry, stay involved in every conversation that’s even tangentially related, and be patient. Domain expertise will follow.
2) Make it easy.
There’s actually very little about data science that’s technically or intellectually challenging – it’s mostly about execution. Sure, machine learning uses advanced concepts that are worth understanding before you build a predictive model, and a passing understanding of statistics is a big deal, but most business questions can be answered with little more than simple arithmetic—what portion of customers do X? How long does it take people to do Y?
What then differentiates good data analysts from the rest? The ability to do this simple analysis quickly and easily, with minimal “friction”, so you can do more analysis faster. A few things help with this:
- Set up “one click” access to data. Shell scripts to drop you directly as a read-only user in your database, libraries to get your data from your database into a clean format in your prefered analysis environment, robots, and data exploration / dashboard type tools all help with this. These aren’t rocket science, but being able to get to your data in under ten seconds means you’ll be able to do it more.
- Have common definitions. Know what “active” means for each of users, accounts, etc. Try to pick consistent time periods for how far back you look at data. If you can skip the figuring out what someone means, data analysis becomes easier.
- Keep a calculator handy. Seriously, the friction difference between a calculator that you’re familiar with at arms reach and having to find one in a drawer, or opening Calculator.app, makes an impact in how easily you can do the simple arithmetic.
- Memorize your database schema. This isn’t a joke. You’ll know what you’re able to be able to find from a database alone and you’ll save a ton of time by not doing
SHOW TABLESandDESCRIBE TABLE Xall the time. At the very least, know what tables are named and generally what the relationship between them is. I’d hazard a guess that if you surveyed the business analytics people at a handful of brand-name internet companies, they could all write out the schemas for their main databases by memory.
3) Look at lots of data.
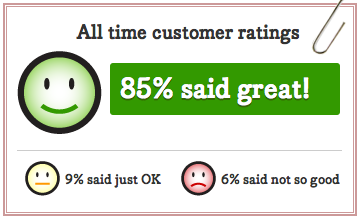
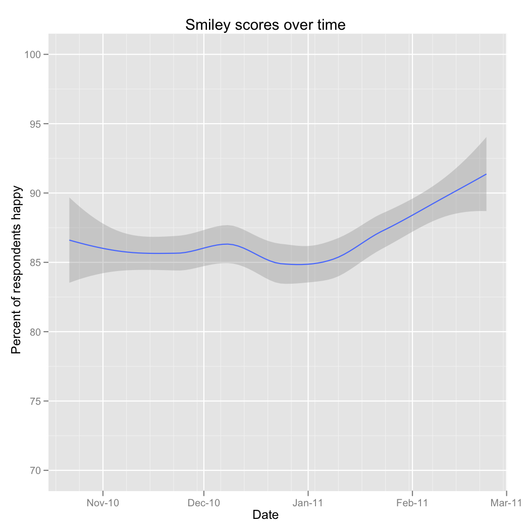
The only way to know what “normal” is when it comes to your data is to look at it, a lot. Look at graphs of different things over different time periods, review log files, read customer emails—be the most voracious consumer of new information and data that you can. Keep finding that next source of information.
Try to spend an hour a day consuming new data – just reading it in, absorbing it, maybe making some notes. It doesn’t need to be for any specific investigation of the moment, but it will pay dividends down the line. This is very similar to the “Rule of 10,000 hours” and other notions of “Just do, a lot”.
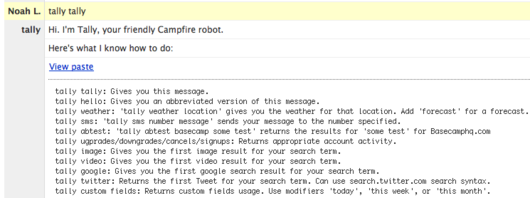
 We use Campfire a lot – it’s our main way of communicating as a team that’s more than half remote. We’ve shared
We use Campfire a lot – it’s our main way of communicating as a team that’s more than half remote. We’ve shared