We’re exploring some very cool ideas to clarify the stream of notes and emails in Highrise. We want to make it easier to scan the streams and differentiate notes from emails from comments. Along the way we’re also cleaning up a lot of complex, overly-DRY code. It’s a great project, but it’s not quite as simple as it sounded at first.
Our initial plan sounded simple:
“Redesign the recording streams.”
“Recording” is an abstraction for the things that appear in streams: notes, comments, emails and more. They’re just notes that appear in a stream, like a blog index. How hard can it be?
When I started working on the new design and touching the code, I realized that recordings have a ton of dependencies. I made a quick and dirty graffle to keep them all in my head:
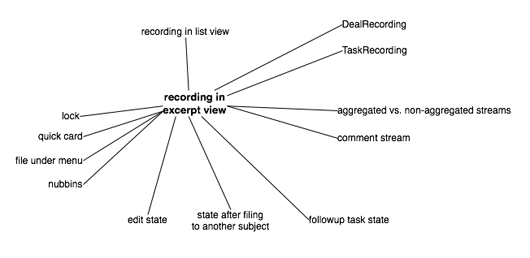
Recordings appear in multiple places: “aggregated streams” like cases and the dashboard, and “non-aggregated streams” like the stream for a particular person. Recordings include comments, and comments are mixed in with all other recordings but also appear in dedicated “comment streams” on recording perma pages. Recordings can be filed, they show privacy status, they have special states if you move them out of the current stream, and on and on. None of these things are obvious at first glance.
And none of this is a problem. We can even use this new design iteration to reduce the complexity. But it’s a good reminder that things often look simpler on the surface. When you dig into an established feature there may be a lot of dependencies and factors that only the source code and some careful spelunking will reveal.
Tony
on 14 Jan 10“factors that only the source code and some careful spelunking will reveal”
That’s an interesting statement. That implies that you guys lean more towards letting the code be the documentation, as opposed to spending a lot of time charting the dependencies of individual entities, etc.
Where you do you fall on the “document everything” <-> “the code is the documentation” extremes?
Mark McSpadden
on 14 Jan 10I’ve started flagging “just” as an indicator that there is probably some over simplification in either the description I’m being given or in my understanding. (Often the later.)
Recognizing and keying on this word, can help snap me out of easy-cake-walk mode back into exploratory mode.
George
on 14 Jan 10What does it mean for code to be “overly-DRY”?
RS
on 14 Jan 10We strongly rely on the code as documentation, and especially the views.
DRY is an acronym from programming circles that means “Don’t Repeat Yourself”. Making your code DRY means removing duplication in order to make the code easier to understand and maintain.
DRY code is well and good, but you can get into trouble if you try to apply the principle to templates. View code gets nasty much faster than other code. It’s often better to just repeat the same template code in a few places than write some special function that generates HTML based on a lot of complex conditions. You could say “overly-DRY” code is one piece of code that tries to do too much in the interest of avoiding duplication, and as a result is hard to understand and hard to change.
Daniel Genser
on 15 Jan 10@RS
How often do you start a project with duplicate pieces of view code only to move toward DRY and vice versa? This decision comes up all the time and it’s interesting to see how other folks deal with it.
Gebze Emlak
on 15 Jan 10How often do you start a project with duplicate pieces of view code only to move toward DRY and vice versa? This decision comes up all the time and it’s interesting to see how other folks deal with it.
This discussion is closed.