
This is the second in a three part series about how we use Twitter as a support channel. Yesterday I wrote about how we use Twitter as a support channel and the internal tool that we built to improve the way we handle tweets.
One of our criteria in finding or building a tool to manage Twitter was the ability to filter tweets based on content in order to find those that really need a support response. While we’re thrilled to see people sharing articles like this or quoting REWORK, from a support perspective our first goal is to find those people who are looking for immediate support so that we can get them answers as quickly as possible.
When we used Desk.com for Twitter, we cut down on the noise somewhat by using negative search terms in the query that was sent to Twitter: rather than searching just for “37signals”, we told it to search for something like “37signals -REWORK”. This was pretty effective at helping us to prioritize tweets, and worked especially well when there were sudden topical spikes (e.g., when Jason was interviewed in Fast Company, more than 5,000 tweets turned up
in a generic ‘37signals’ search in the 72-hour period after it was published), but had it’s limitations: it was laborious to update the exclusion list, and there was a limit placed on how long the search string could be, so we never had great accuracy.
When we went to our own tool, our initial implementation took roughly the same approach—we pulled all mentions of 37signals from Twitter, and then prioritized based on known keywords: links to SvN posts and Jobs Board postings are less likely to need an immediate response, so we filtered accordingly.
Using these keywords, we were able to correctly prioritize about 60% of tweets, but that still left a big chunk mixed in with those that did need an immediate reply: for every tweet that needed an immediate reply, there were still three other tweets mixed in to the stream to be
handled.
I thought we could do better, so I spent a little while examining whether a simple machine learning algorithm could help.
Lessons from email
While extremely few tweets are truly spam, there are a lot of parallels between the sort of tweet prioritization we want to do and email spam identification:
- Have some information about the sender and the content.
- Have some mechanism to correct classification mistakes.
- Would rather err on the side of false negatives: it’s generally better to let spam end up in your inbox than to send that email from your boss into the spam folder.
Spam detection is an extremely well studied problem, and there’s a large body of knowledge for us to draw on. While the state of the art in spam filtering has advanced, one of the earliest and simplest techniques generally performs well: Bayesian filtering.
Bayesian filtering: the theory
A disclaimer: I’m not a credentialed statistician or expert on this topic. My apologies for any errors in explanation; they are indavertent.
The idea behind Bayesian filtering is that there is a probability that a given message is spam based on the presence of a specific word or phrase.
If you have a set of messages that are spam and non-spam, you can easily compute the probability for a single word – take the number of messages that have the word and are spam and divide it by the total number of messages that have the word:
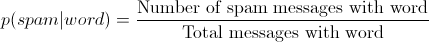
In most cases, no single word is going to be a very effective predictor, and so the real value comes in combining the probabilities for a great many words. I’ll skip the mathematical explanation, but the bottom line is that by taking a mapping of words to emails that are known to be spam or not, you can compute a likelihood that a given new message is spam. If the probability is greater than a threshold, that email is flagged as spam.
This is all relatively simple, and for a reasonable set of words and messages you can do it by hand. There are refinements to deal with rare words, phrases, etc., but the basic theory is straightforward.
Building a classifer
Let’s take a look at the actual steps involved with building a classifier for our Twitter problem. Since it’s the toolchain I’m most familiar with, I’ll refer to steps taken using R, but you can do this in virtually any language.
Our starting point is a dataframe called “tweets” that contains the content of the tweet and whether or not it needed an immediate reply, which is the classification we’re trying to make. There are other attributes that might improve our classifier, but for now we’ll scope the problem down to the simplest form possible.
After some cleaning, we’re left with a sample of just over 6,500 tweets since we switched to our internally built tool, of which 12.3% received an immediate reply.
> str(tweets) 'data.frame': 6539 obs. of 2 variables: $ body : chr "Some advice from Jeff Bezos http://buff.ly/RNue6l" "http://37signals.com/svn/posts/3289-some-advice-from-jeff-bezos" "Mutual Mobile: Interaction Designer http://jobs.37signals.com/jobs/11965?utm_source=twitterfeed&utm_medium=twitter" "via @37Signals: Hi my name is Sam Brown - I’m the artist behind Explodingdog. Jason invited me to do some draw... htt"| __truncated__ ... $ replied : logi FALSE FALSE FALSE FALSE FALSE FALSE ...
Even before building any models, we can poke at data and find a few interesting things about the portion of tweets that needed an immediate reply given the presence of a given phrase:
| Word | Portion requiring immediate reply |
|---|---|
| All tweets | 12.3% |
| “svn” | 0.2% |
| “job” | 0.5% |
| “support” | 17.3% |
| “highrise” | 20.8% |
| “campfire” | 26.9% |
| “help” | 35.4% |
| “basecamp” | 49.5% |
This isn’t earth shattering—this is exactly what you’d expect, and is the basis for the rudimentary classification we initially used.
With our data loaded and cleaned, we’ll get started building a model. First, we’ll split our total sample in two to get a “training” and a “test” set. We don’t want to include all of our data in the “training” of the model (computing the probabilities of a reply given the presence of a given word), because then we don’t have an objective way to evaluate the performance of it.
The simplest model to start
I always like to start by building a very simple model – it helps to clarify the problem in your mind without worrying about any specifics of anything advanced, and with no expectation of accuracy. In this case, one very simple model is to predict whether or not a tweet needs a reply based only on the overall probability that one does – in other words, randomly pick 12.3% of tweets as needing an immediate reply. If you do this, you end up with a matrix of predicted vs. actual that looks like:
| actual | ||
|---|---|---|
| predicted | FALSE | TRUE |
| FALSE | 2878 | 374 |
| TRUE | 402 | 51 |
Here, we got the correct prediction in 2,929 cases and the wrong outcome in 776 cases; overall, we correctly classified the outcome about 79% of the time. If you run this a thousand times, you’ll get slightly different predictions, but they’ll be centered in this neighborhood.
This isn’t very good, for two reasons:
- As gross accuracy goes, it’s not that great—we could have built an even simpler model that always predicted that a message won’t require an immediate reply, because most (about 88%) don’t.
- We classified 374 messages that actually did need an immediate response as not needing one, which in practice means that those people wouldn’t get a response as quickly as we’d like. That’s a pretty terrible hit rate—only 12% of tweets needing a reply got one immediately. This is the real accuracy measure we care about, and this model did pretty terribly on that regard.
Building a real model
To build our real model, we’ll start by cleaning and constructing a dataset that can be analyzed using the “tm” text mining package for R. We’ll construct a corpus of the tweet bodies and perform some light manipulations – stripping whitespace and converting everything to lower case, removing stop words , and stemming. Then, we’ll construct a “document term matrix”, which is a mapping of which documents have which words.
require(tm) train_corpus <- Corpus(VectorSource(training$body)) train_corpus <- tm_map(train_corpus, stripWhitespace) train_corpus <- tm_map(train_corpus, tolower) train_corpus <- tm_map(train_corpus, stemDocument, "english", stemmer="Rstem") train_dtm <- DocumentTermMatrix(train_corpus)
With stopwords removed, the list of frequent terms begins to resemble the vocabulary of things that are talked about related to 37signals:
findFreqTerms(train_dtm, 150)
- ”...”
- ”@jasonfried”
- “advice”
- “apple”
- “basecamp”
- “bezos”
- “competing”
- “creep”
- “design”
- “easy”
- “fried”
- “goal”
- “hiring”
- “http://37signals.com/svn/posts/*”
- etc
The presence of ”...” in the frequent terms list above might seem a little confusing. It makes more sense when you take a look at some of the original tweet bodies – many services that automatically tweet from RSS feeds or retweets shorten the content and use ellipses to indicate that there is more content that’s not included. Though often you remove punctuation in this sort of analysis, I’ve left these in our dataset. I have a hunch they’ll be important—most people who are manually writing tweets and need help immediately aren’t using ellipses.
For simplicity, we’re also only going to consider the probabilities for single words; you could build a similar model using bigrams (two word phrases) or longer, but for these purposes, we’ll focus on the simple case.
The document term matrix we’ve ended up with is what’s known as “sparse” – we have about 5,800 unique terms spread across 3,000 or so “documents” (tweets), but most tweets don’t have most words. If you imagine a grid of tweets on one axis and terms on the other, just one tenth of one percent of the 19 million possible combinations are filled in.
The “long tail” of terms that were used once usually adds significant computational complexity without much improvement in predictive accuracy, so we’ll prune those off our matrix:
train_dtm <- removeSparseTerms(train_dtm, 0.99)
This dramatically drops the size of our matrix—from 19 million combinations to around 300,000. This also means that we’re dropping from 5,800 terms to just the 100 or so that occur most frequently (a later re-running of the model with larger numbers of words didn’t meaningfully impact the accuracy compared to the 100-word version, but did have a 50x impact on runtime).
With all of our data preparation done, we can build the actual model. It’s not terribly hard to implement Naive Bayes from scratch in any programming language, and I’d encourage you to do just that – it’s a good exercise in both programming and probability. Practically, there’s no business value in reimplementing algorithms, so I usually use someone else’s hard work, in this case through the ‘e1071’ package.
require(e1071)
# Create a matrix from the document term matrix and normalize to examine only the presence or absence of a word, not the frequency.
norm_train <- inspect(train_dtm)
norm_train <- norm_train > 0
# Convert to a dataframe and vectorize
train_df <- as.data.frame(norm_train)
for(i in 1:length(train_df)) {
train_df[,i] <- as.factor(train_df[,i])
}
# Build the model - compute the probabilities of each term
model <- naiveBayes(train_df, as.factor(training$replied), laplace=1)
# Make prediction on the held-back test/evaluation dataset
pred <- predict(model, test_df)
#Compare prediction and actual
table(pred, evaluation$replied)
When done, we end up with a comparison of prediction vs. actual again:
| actual | ||
|---|---|---|
| predicted | FALSE | TRUE |
| FALSE | 2898 | 30 |
| TRUE | 400 | 402 |
Overall, this model gets about 89% of predictions correct – somewhat better than our naive model (about 79%), a model that always picks ‘no immediate response needed’ (about 88%), and better than our keyword based approach (about 65% gross accuracy).
More significantly, it has a false positive rate of about 7% (7 out of every hundred tweets that do require an immediate response will be categorized as not needing one), compared to 88% for our naive model.
Compared to our original methodology of prioritizing just based on keywords, we’ve raised the portion of non-urgent tweets we’re filtering out from 60% to nearly 90%, which dramatically lowers the volume of potentially high priority tweets to review.
What’s next?
This is about the result I expected from the time invested (a couple hours, including trying a range of variations not shown here) – it beats both our original implementation and our naive implementation on most of the measures we care about.
In the third and final part of this series, I’ll talk about what we did with the results of this model and how it impacted the business on a practical level.
Michael
on 14 Nov 12I really enjoyed this post. Thanks for showing R in action.
Vlad
on 14 Nov 12Awesome work Noah… I’ve been teaching myself R for a few months now and this is one of the most practical articles I’ve read so far. If you write a book I’ll buy it!
Chris
on 15 Nov 12Pretty cool, reminds me of my university dissertation which was an “Automatic Text Summarizer”, it used pretty much the exact frequent terms algorithm you’re describing here on a research paper and then used the word frequency count to apply a score to each of the sentences therein. The five highest scoring sentences were pulled to create the summary.
The difference being my paper took 12 weeks to produce whereas your experiment only took “a couple hours”. Ah, college days.
odnsjnfr
on 20 Nov 121
This discussion is closed.