This fall I’ve been taking the Rails for Designers class at The Starter League here in Chicago.
My classmates come from as far as South America and as close as a few desks down (fellow 37signals designers Jamie, Mig, Jonas, John, and Shaun are also taking the class). One student, not in our class, came over from Hong Kong.
My classmates also come from a variety of backgrounds. Some are designers with no programming experience. Others are programmers who work in languages other than Ruby. There’s also a lawyer and a couple Chicago Public School teachers, too. There’s a good 30 year age range spread as well. It’s a diverse and dedicated group. They’re inspiring people.
Class ends in a few weeks, and applications for the next quarter close in a few days, so I thought it would be a good time to reflect on the experience.
Was it worth it? Absolutely. Would I do it again? Absolutely. Would I recommend it to someone else? Absolutely.
I’ve been around Rails since the beginning. At 37signals, designers and programmers work together on the same codebase, so every 37signals designer has seen plenty of Rails in their time. And I’ve tried to pick it up on my own over the years by reading books or getting a few crash courses from co-workers. But it never clicked like it does now after taking this Starter League class.
I think the magic is in how Jeff and Raghu, the two teachers, understand how to teach absolute beginners. Teaching beginners is a unique skill. It requires a ton of patience and a truckload of empathy. You really have to start right at the beginning and assume nothing about what people may or may not know. You have to think like a beginner again. That’s really hard.
Am I a fantastic programmer now? No way. Would I hire myself as a programmer at 37signals? No, I wouldn’t. But that wasn’t my personal goal.
However, after just a few months I have a solid basic understanding of Ruby, Rails, and what programming is all about. I can build a database-backed web app on my own. I can pull in data from external APIs, manipulate it, and return it formatted the way I want. I can read and understand a bunch of code in the Basecamp code base that was complete greek to me before. I know what this code does, why it is where it is, how to manipulate it enough not to break the basics, and how to make changes without having to ask for help. That’s a huge leap forward for me, and it means fewer “hey, can you do this for me?” questions for my co-workers.
I can’t tell you how liberating it is to be able to find my way around our codebase now. It makes me a better designer, too. I can quickly prototype new ideas without having to get someone else involved. Big win. Further, I know where to go from here if I want to dedicate myself to getting better.
And on top of all of this, I feel like I’ve gained an invaluable skill: The ability to see problems from a new angle. Learning how to program has introduced me to a new perspective on problem solving, a new way of thinking. That doesn’t come around often and I’m thrilled to have found it at The Starter League.
If you’re interested in learning Rails – even if you don’t have a single bit of experience – check out The Starter League’s Web Development Class. Just want to learn HTML/CSS? Check out the HTML/CSS class (and there’s an advanced HTML/CSS class, too). There’s even a User Experience Design class. Want to learn visual design or how to improve your current design skills? Our very own Mig Reyes is teaching the Visual Design class.
Applications for The Starter League Winter session are due by Sunday. If you’re on the fence, hop off and apply. You will not regret it.
(Disclosure: 37signals is a minority investor in The Starter League)

 The way we book a beta server for use with a certain branch is simple: It’s just in the title of the
The way we book a beta server for use with a certain branch is simple: It’s just in the title of the 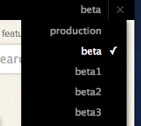 To select a given beta server, we’ve added a drop-down to all 37signals’ staff accounts within Basecamp itself.
To select a given beta server, we’ve added a drop-down to all 37signals’ staff accounts within Basecamp itself.