When I’m not analyzing data, I like to make things from wood—furniture, cutting boards, etc. Making something physical after sitting at a computer all day is relaxing and rewarding, and I’m never short on gifts for family and friends.
My woodworking isn’t totally detached from technology, and I rely heavily on forums, websites, online magazines, and YouTube both for inspiration and to learn how to do things. I’ve learned most of what I know about woodworking from people on the Internet, and I’ve been inspired to tackle things that I never would have thought of otherwise.
There’s a downside to seeing all this creation on the Internet—you aren’t seeing the reality of the process. You see someone make an amazing bowl or cutting board in 6 or 12 minutes. Even on the long side, it’s rare to see something creative boiled down to more than an hour of footage or a couple dozen photographs and a few thousand words.
When you compress things down to a shareable size, you miss a lot. What you don’t see is the unglamorous parts: the sharpening of the chisels, the unclogging of your glue bottle, or the parts that don’t fit together. You don’t see the days where you are too tired or unmotivated to go down and work on anything at all, or those cases where life interferes and a “easy one weekend project” ends up stretching to six or twelve months.
This same phenomenon appears in sharing about web design and software. You see a major new version of a mobile app compressed into a few thousand words or an animation in a dozen GIFs, but you don’t see the day lost to fighting Xcode issues or waiting for things to render. You don’t see the mornings where you end up reverting the previous day’s commits entirely.
Any creative endeavor is highly non-linear, but the sharing of it almost always skips a lot of the actual work that goes into it. That’s ok; a clear progression makes for a good story that’s easy to tell. But don’t judge your reality against someone else’s compressed work. It’s ok if it takes you a day to make a cutting board like one that someone made in six minutes on YouTube; the truth is it probably took them a day too.
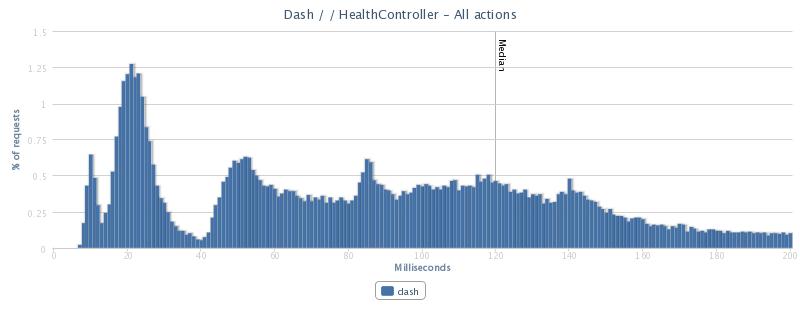
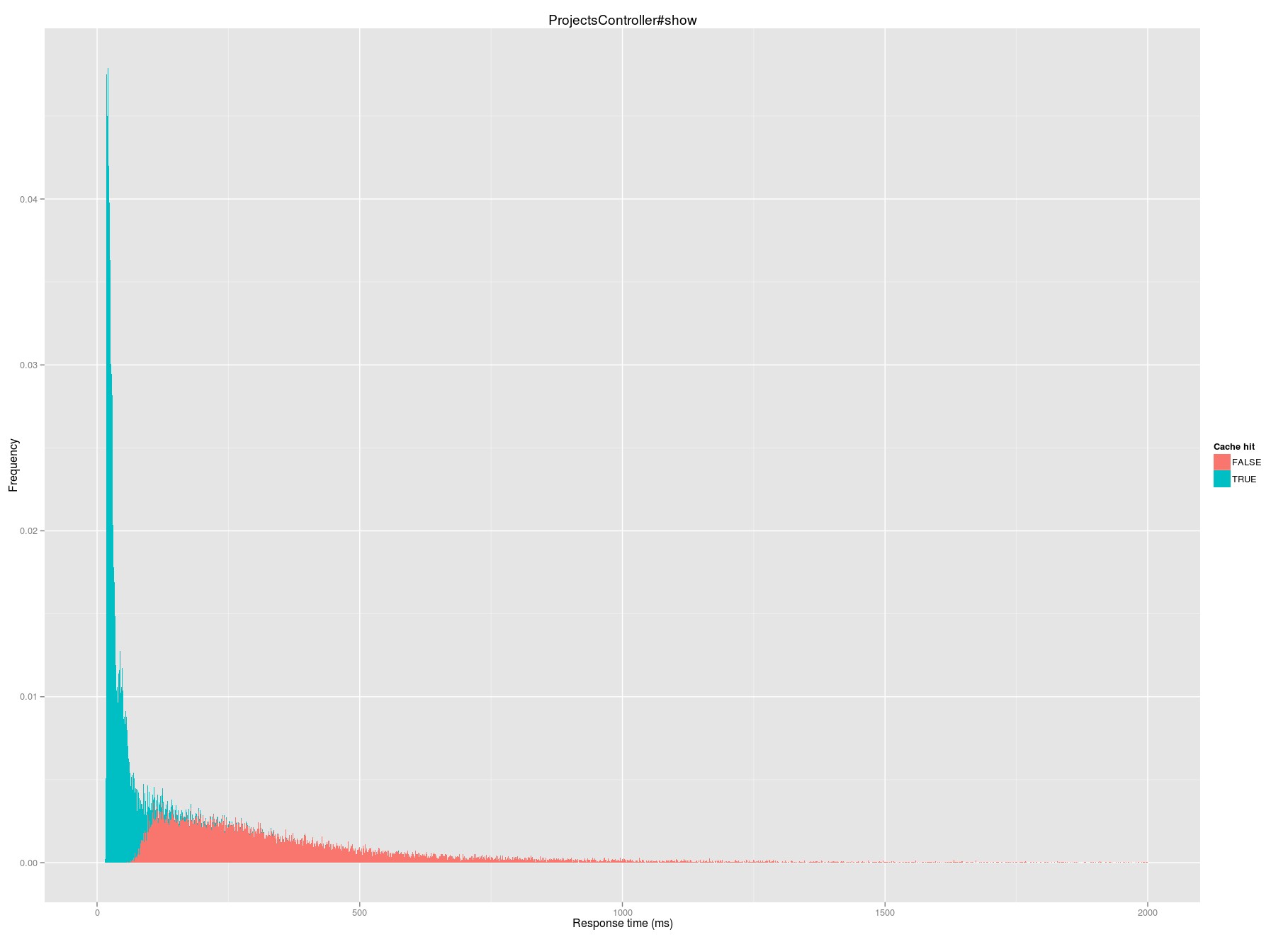 Median request time on a cache hit is 31 milliseconds; on a miss it jumps to 287 milliseconds.
Median request time on a cache hit is 31 milliseconds; on a miss it jumps to 287 milliseconds.